
软件体系结构
P2
public interface MovieFinder{
List findAll();
}
public class MovieLister{
private MovieFinder finder = new MySpecialMovieFinderImp(); // BAD
public Movie[] moviesDirectedBy(String arg){
List allMovies = finder.findAll();
for (Iterator it = allMovies.iterator(); it.hasNext();){
Movie movie = (Movie) it.next();
if (!movie.getDirector().equals(arg)) it.remove();
}
return (Movie[]) allMovies.toArray(new Movie[allMovies.size()]);
}
}为什么不好:指定了 finder,编译好后无法修改字节码,使得 finder 与原来的耦合了,因此需要由第三方把 listener 和 finder 组装起来,二者的开发是完全独立的,只要注意遵守接口规范即可
由 assembler 来把依赖关系注入到系统中
装配器==构建容器
P3
SoC:separation of concern(关注分离)
P4
BS/CS 架构
business server/client server
三层划分(three layer,2-tier)
- Data
- Application Logic
- Presentation
thin/fat 的概念:哪一方做更多的工作
3-tier:资源共享,集中化管理,性能分布,安全
- Tier-1:前端
- Tier-2:业务层
- Tier-3:数据层
UI 模板:在 html 代码中留下占位符,等到后面别人写好后填进去
- 展示层和业务逻辑层分离
MVC
- M:核心数据功能
- V:从 Model 获得数据显示给用户
- C:处理事件操作的模型
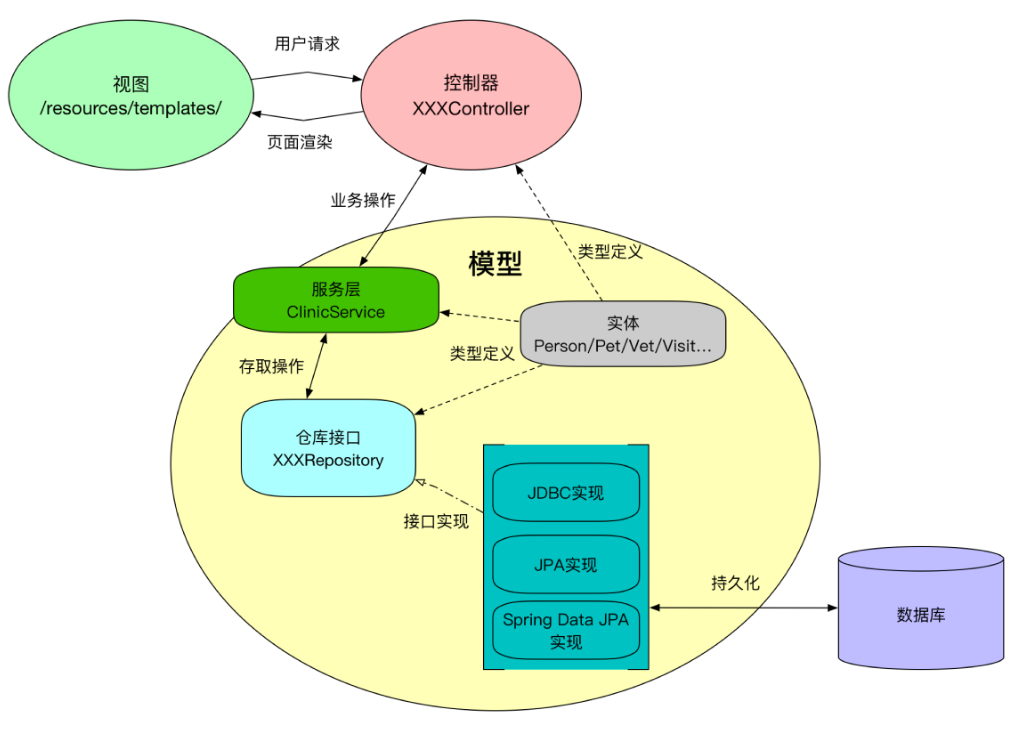
REST
资源表现层状态转化(返回原始数据(json),由前端来渲染)
为什么 REST
- MVC 开发者,需要知道 UI 模板中,哪些地方要和后台进行交互,展示和模型混合在一起
- 接口不标准
核心概念
- 资源:被引用到的,就是资源,用 URI 标识
- 表现:把资源呈现出来的形式,如 HTML、JSON
- 状态转移:客户端与服务端的交互是无状态的,每次请求中包含所需的一切信息
- 服务端不保留应用状态,独立相应请求,便于扩展
用户状态就是应用状态,服务器状态是资源状态
pos 机服务器不应该记住应用状态,这样才保证客户端与服务器之间是无状态通信。想想多台服务器的情况,一台服务器记住了用户状态,那用户向另一台服务器发起请求时怎么办?
服务端还是要在资源中提供“下一个状态”,例如加一个 URI,客户端使用统一接口获取下一个状态的资源(在 Link 头提供链接)
可扩展
可扩展:假如有一个服务器提供算 pi 的服务(计算密集型),多个用户同时请求服务的话可能会超时
L4 负载均衡:虚拟 IP + 端口,转发给真实 IP
L7 负载均衡:根据域名或 URI 寻找对应服务的 IP,转发到交具体服务器
- 为何需要 L7:便于处理应用层协议,根据 URI 转发请求
- 为何需要 L4:L7 性能不如 L4
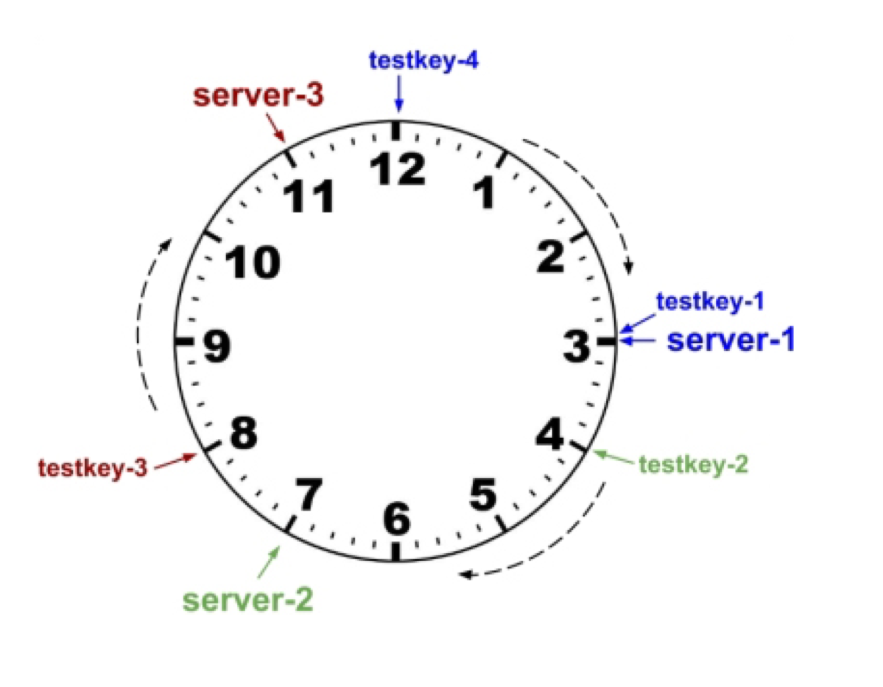
Redis 哈希划分
- 基本方案:
hash(key)%n,但问题是n在变化怎么办 - 一致性哈希:将 server 标识与 key 映射到同一个值域空间,也就是把 server 和 key 都做一个 hash,形成一个钟表的形状,key 落位后顺时针找到最近的 server 映射点
知识点
Spring cache
一致性哈希
Session,Spring bean scope
可扩展,分布式系统
- 服务拆分
- 冗余
- 分区
- 如何实现可扩展数据访问
- 缓存
- 代理
- 索引
- 负载均衡
- 队列
微服务
- 为什么:所有功能写在单个应用的话,水平向扩展的时候需要把全部代码都复制一遍
注册服务:服务与服务之间可以互相找到,且是负载均衡的(相当于 dns,提供一个名服务)
config-server:目录,字典,管理所有配置
微服务的缺点:网线传输是不可靠的,存在调用雪崩现象,这时就需要断路器
Spring 的 starter 就可以帮我们自动配置需要的依赖(主要是创建 bean),因此很方便就运行起来,这是 auto configure 技术
Serverless
FaaS:考虑 rest 接口的幂等性,函数式编程的幂等性
把没有副作用的功能做成一个 function
管道-过滤器架构
Data Source --(Pipe)-- Filter --(Pipe)-- Data Sink
优点
- 过滤器可重用,可替换
- 高效并行
缺点
- 数据传输、转换开销大
- 错误定位、处理较复杂
Spring Batch 流程图 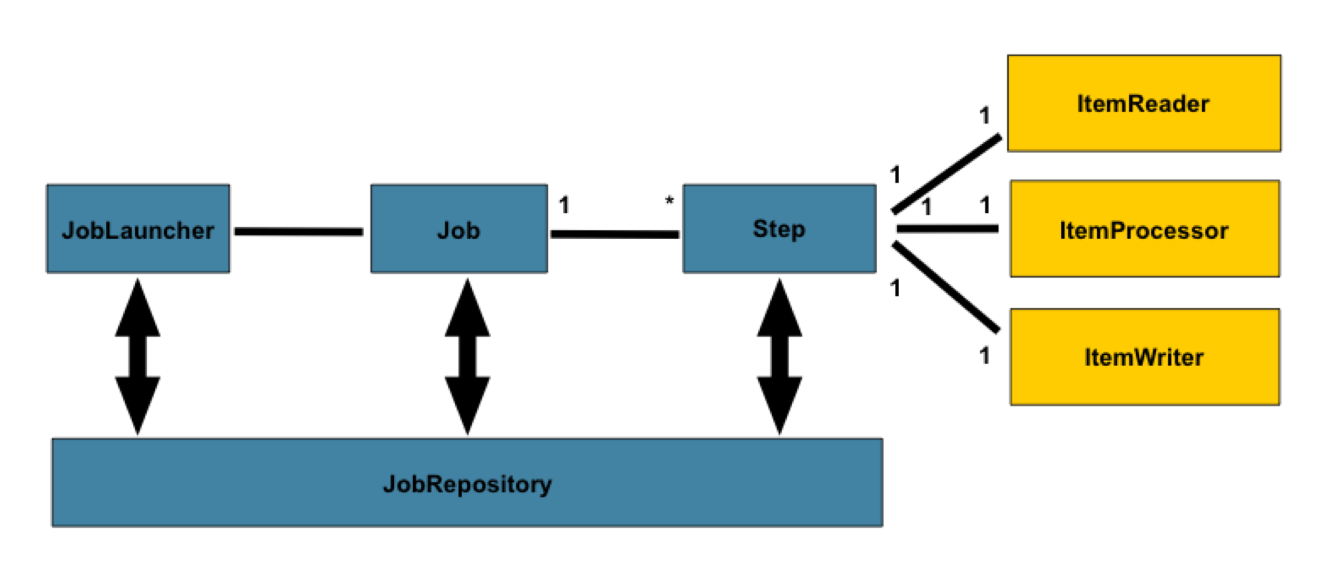
read-write 过程是 chunk-oriented processing
流式处理
- 顺序 flow,用
next()把 step 串起来 - split(parallel) flow,几个 step 并行执行
可扩展性
- 用
taskExecutor创建线程池,一个 step 多线程运行 - partitioner 对一个 step 进行分区分片
消息驱动架构
- 观察者模式:subject notifys observers
- pub-sub 模式:publisher 根据 topic 通知 subscribers(中间有个 channel)
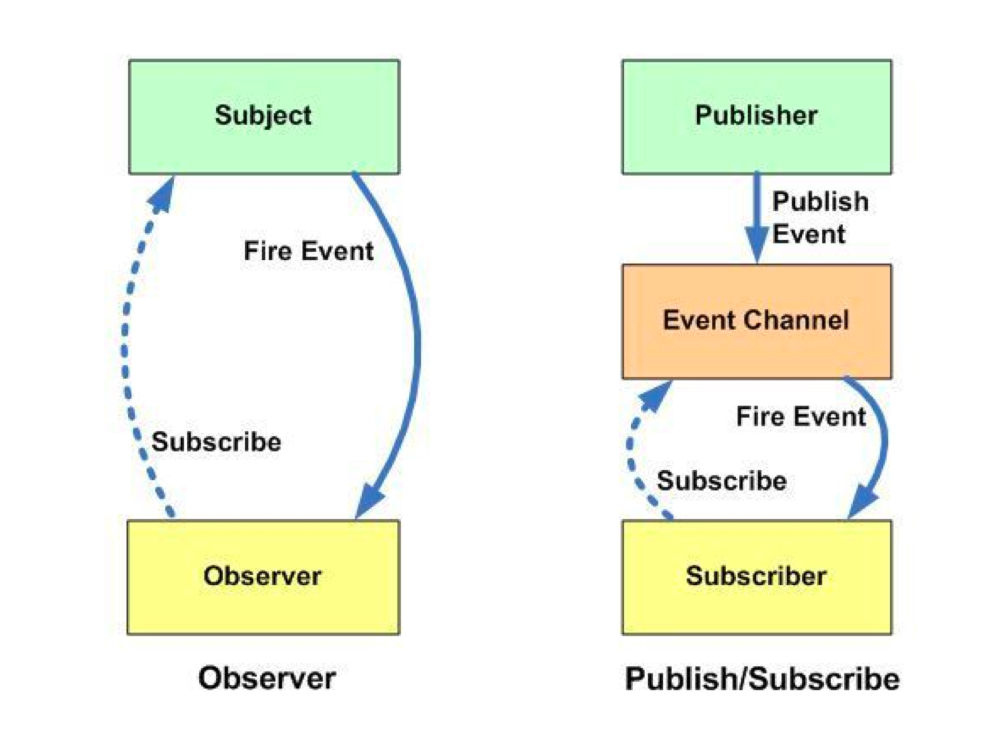
Async listener:这里的异步要保证对于 UI 的更新放在主线程中执行,一般是被通知者把更新操作发送到主线程的调度队列中
aw01
构件系统:引入 spring-context
把需要注入的属性标注成
@Autowired把作为构件的类标注成
@Component配置类,标注成
@Configuration- 提供所有返回构件的方法,标注成
@Bean
- 提供所有返回构件的方法,标注成
使用Spring Boot Maven Plugin的功能
- 设置后,使用
mvn spring-boot:run一键编译运行,非常方便 - 不指定 main 也行,它会自动找到
Autowired 是根据类型来找的,如果有两个返回 int 的 bean,就会报错,二义性,这时通过在 bean 的下一行加一个 @Qualifier 来指定
aw02
pom 的 java 版本是 21,真的有必要吗
在购物车为空时调用 a 会报错,考虑改为打印提示
aw03
什么是 model 对象,往模型对象添加参数,以改变对象,然后返回字符串,即在模板中更改
html 模板是用 Thymeleaf 模板引擎做的,只要是 th: 开头的都是交给引擎来计算渲染的
aw04
restController 的含义是本身是 controller,返回结果要渲染成 responsebody
Getmapping 注释的作用是把返回值序列化成 json 字符串,因此在浏览器上可以看到 json
Windows 上不行是因为 找不到 json-server 模块:解决方案是安装低版本的 json-server,这是从 https://github.com/typicode/json-server/issues/1500 上看到的
Windows 上运行 json-server 还会提示禁止运行脚本,解决方案是设置 Windows 的 executionpolicy,在管理员 powershell 中 set-executionpolicy remotesigned
怎么办呢,还是存在 Access to XMLHttpRequest at 'http://localhost:8080/product' from origin 'null' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. 这个问题
通过 F12 查看网络请求发现,问题出在响应头没有支持跨域访问,突然想到这可能是 spring 的问题,于是搜索 spring 项目开启跨域支持,用一个简单的在 Controller 上添加 @CrossOrigin 注解可以暂时解决这个问题
aw05
Jpa 的 insert 操作不支持?改用 save(),这是一个库函数?都不用自己写任何实现的
把 json_img 变成空字符串,就可以从在线地址获取图片了
- 配置 redis,在 application 加注释,在 JD 类 getProduct 那里加注释
- 在 application.properties 里加设置
- 改 pom
支持 session:
- 改 pom
用 jib 把 spring 项目打包成 docker 镜像,在 pom 中添加一个 plugin
mvn clean compile jib:dockerBuild
要在构建的终端那里使用 docker login -u xxx 登录之后,才成功构建
运行命令:docker run -d --name webpos-0.5 --cpus=0.5 -p 18080:8080 webpos:0.0.1-SNAPSHOT (其中 -d 是 daemon)返回哈希值,用 docker ps 查看进程
http-server 'dist' -c-1 -p 3000 -o
用 docker ps 查看 docker 进程
用 docker stop xxx 停止运行
用 docker ps -a 会发现还在,因此要用 docker rm xxx 删掉它
用 docker rmi xxx 删除 image
要改变 spring 项目绑定的端口:SERVER_PORT=8081 mvn spring-boot:run
由于 haproxy 采用了轮询的形式,即使用户登录了,下一次访问时会把 i 的 cookie 发到 i+1 号节点导致登录失效
Spring 开启缓存支持:注释、pom、application 配置
一致性哈希:server 们的值域在一个环上,管理一段区间
创建集群:本地创建(见 redis-cli --cluster help、docker、手动创建
Redis hash slot:hash 后取模,根据值域落到对应的 slot 中
Tomcat cluster:每个 cluster 将 session 同步到所有节点上,但是性能很差
Spring 可以用 jdbc 把 session 数据存到数据库里,但一般都是用 redis
- Product 类要实现 serializable 接口(原来博客早就提到这个了,怎么没有早点看到啊)
原来 you MUST CACHE the products from jd.com otherwise you'll get yourself blocked 这句话指的是压测 jd.com 的时候并发数量高,可能会同时向京东发送大量请求,导致 ip 被 ban,正确的做法是先手动刷新一次,然后再做压测,实际测的是数据库读写的性能!为此浪费一个晚上了!
水平向扩展并没有设计目标,因此效果不明显,需要自己造一个瓶颈出来
aw06(🔗)
课上用的 demo 仓库:https://github.com/paulc4/microservices-demo
CSLB:客户端负载均衡,指的是加了 lb 注释后,account 服务在 eureka 中注册多个实例后,用户端在解析的时候就会确定向谁发送请求
Pet clinic 版本:在 config 服务的配置中包含了一个 git 仓库,其他服务启动的时候,向 config 发送请求得到某个特定 yml 文件,config 从仓库中取出来给它
断路器 例子:spring-circuitbreaker
springboot:依赖 starter 实现一键启动,内部靠 autoconfig 创建组件
为什么需要注册服务
- 微服务是动态变化的,如扩展、升级、死机。注册服务就可以跟踪并提供最新信息
- 负载均衡,因为可以知道每个服务的情况
- 帮助微服务之间互相发现
- 监控、管理,提供整个系统的大纲
网关层的好处
- 路由,修改微服务层不影响客户端
- 负载均衡(网关服务也是要注册到 eureka 的,从 eureka 那里获得其他服务的 IP)
- 缓存一部分 requested data
- 安全性,提供验证和授权
- 监控所有 API 请求,便于诊断问题
微服务例子 https://github.com/senuravihanjayadeva/Spring-Microservice/tree/main
断路器例子 https://github.com/SalithaUCSC/spring-boot-circuit-breaker/tree/main
TODO:创建订单服务之后,通过 restTemplate 向 product 端发送 crud 请求
❗ 被困住的无法转发问题,原因是依赖项是 spring-cloud-starter-gateway-mvc,应改成 spring-cloud-starter-gateway,因为两者的配置方式不一样的
测试 product 端的 post 接口
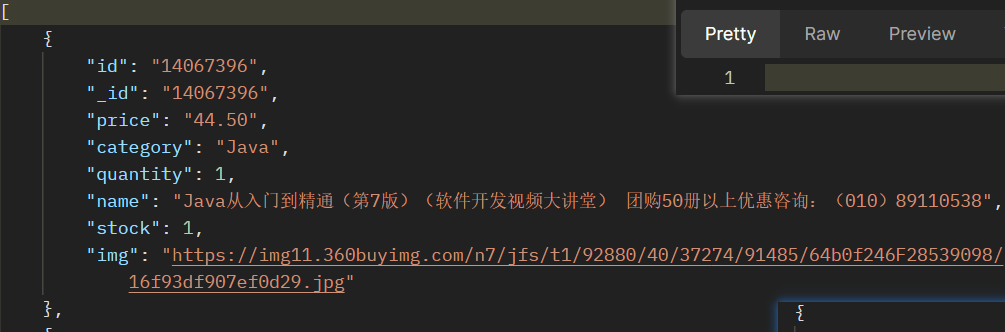
可以看到成功更新了
⚠placeOrder 是一个事务,但是调用 get 的时候识别不到这个事务
更新之前
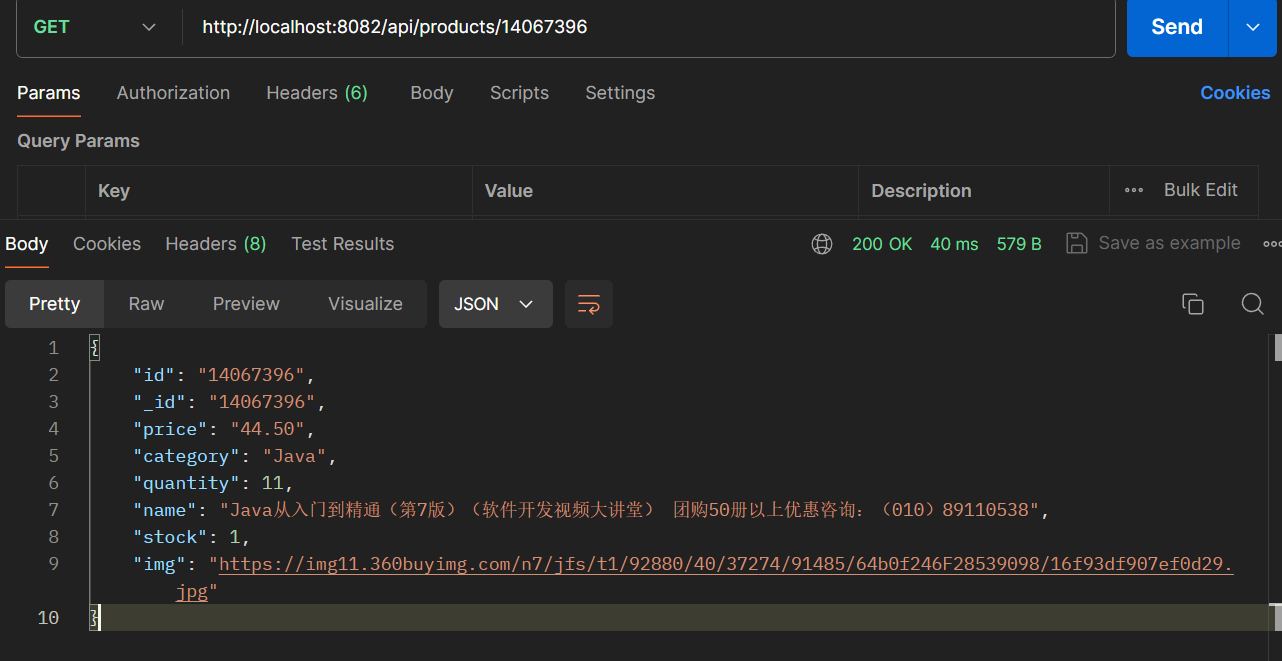
更新的状态码
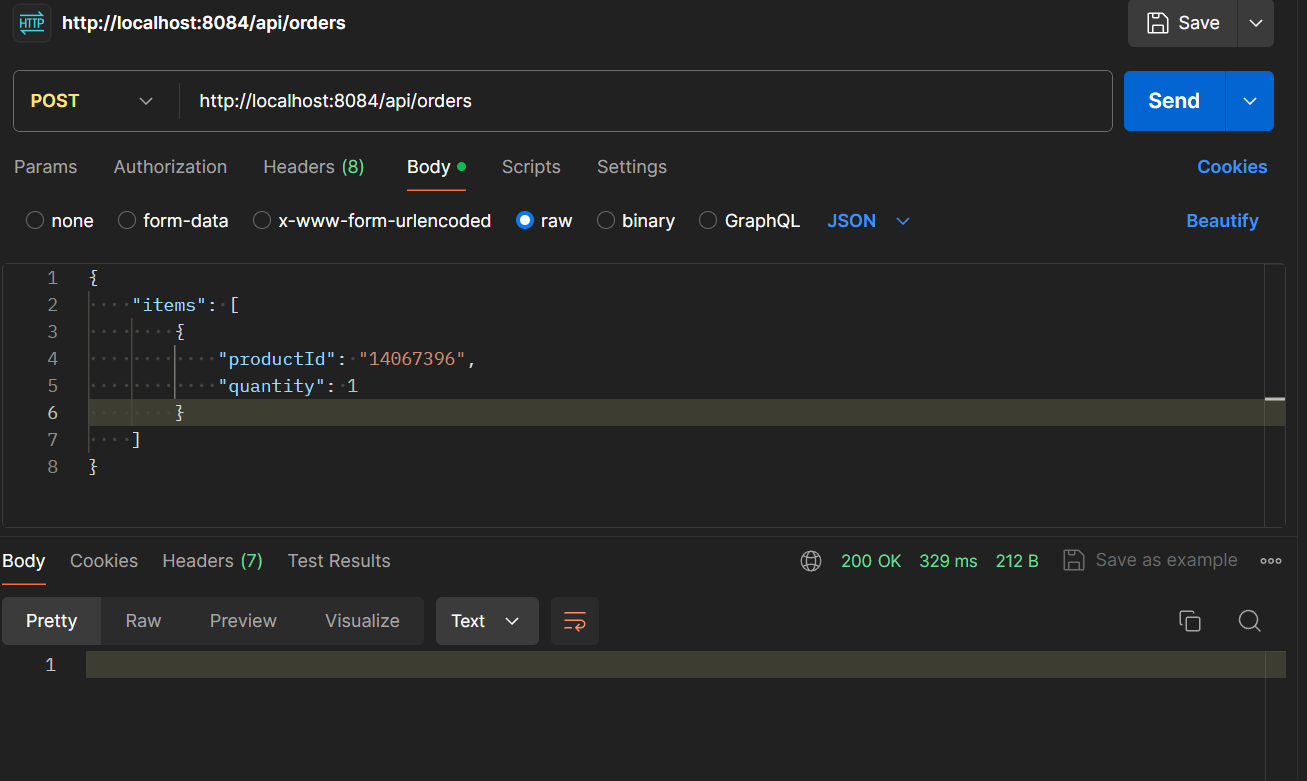
更新之后的值,可以看到确实减少了
Resilience4JCircuitBreakerFactory 的配置好像都是一样的,没有区别,这里就作为一个占位作用吧
断路器的行为:有一个状态转换机和滑窗,多次调用失败会进入 快速失败 阶段,直接拦截所有请求
- 配置了 fallback 方法后,调用失败就会执行这个 fallback 方法
- 但是 throwable 的东西不同(前几次是调用失败的信息,后面是断路器已开启的信息)
TODO:配置预检 preflight 的响应(网关层配置 ✔)
连接 mysql 之后,数据被持久化了,所以不是每次都更新商品信息的
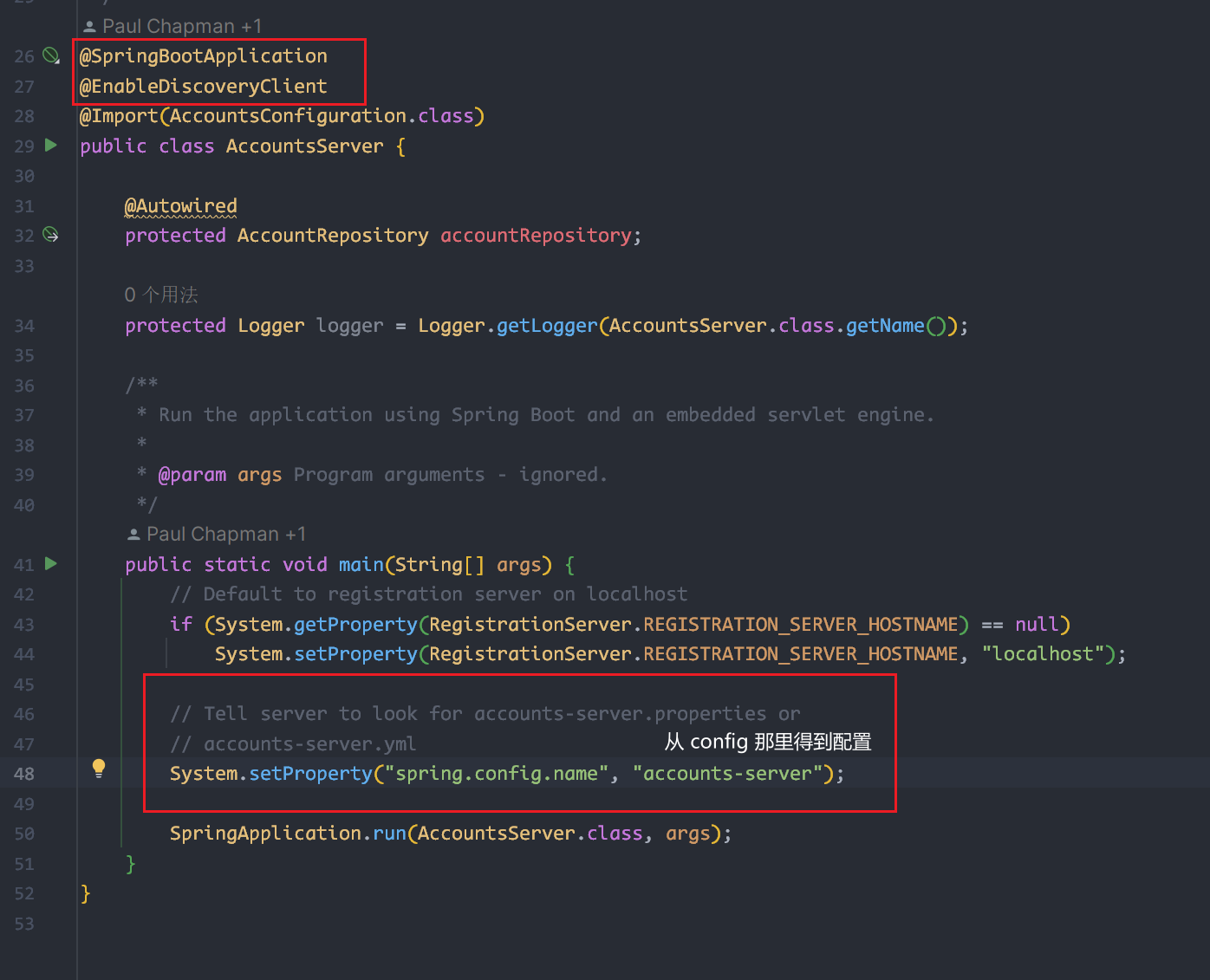
System.setProperty("spring.config.name", "accounts-server"); 是用于指定应用启动时加载的配置文件,不设置的话就会加载默认那个
网关配置,需要每个路径配一个路由,因为不支持 or 操作,只支持 and 操作
修改前端代码,使得 json 符合格式,能够被转发和识别
测试:增加多个商品同时下单,成功
客户端 lb:url 用服务名替代,在 restTemplate 中添加 loadbalance 注释(加在构造函数那里!)
但是要修改 product 服务,运行多个实例的时候在不同的端口开启服务
- 在 main 类的 args 获得端口信息,用 mvn package 打包后,通过 java -jar 运行并指定参数
- 自己输入的 args 不影响 application 的配置

然后怎么配置网关:转发目标改为 lb://服务名
经过测试,确实实现了转发

8081 的实例被访问 4 次
8082 的实例被访问 2 次
实现了网关转发层的 lb
但是在测试下单时,有意思的事情发生了,在 8081 端口执行了 select for update 操作(加锁),但是实际更新时发给了 8082 端口来执行 update
断路器的作用?在断网的情况下比较明显,或者人为设置一个 sleep,就可以得到默认结果
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException ignored) {
}
Docker 运行镜像时创建的隔离环境,称为容器
mysql 可以在 compose 中设置
TODO:搞明白怎么把初始化脚本上传到容器中
网络问题可以在 compose 中进行配置
TODO:测试注册服务和转发服务是否可行
由于开启了容器间网络,各个服务互相访问的话,要通过服务名来访问,这一点需要在 compose 中设置
目前来看只需要让各个服务都注册到 eureka 就可以了,服务间通信由 eureka 解决
为了让宿主机也能访问到容器的服务,port 映射还是要做的
接下来打算按照 gpt 给出的文件目录和 compose 进行配置
myproject/
├── serviceA/
│ ├── Dockerfile
│ └── app.jar
├── serviceB/
│ ├── Dockerfile
│ └── app.jar
├── serviceC/
│ ├── Dockerfile
│ └── app.jar
└── docker-compose.yml
Dockerfile
# 使用OpenJDK 11作为基础镜像
FROM adoptopenjdk/openjdk11:jre-11.0.12_7-alpine 先拉取一下最新的 jdk 镜像
# 设置工作目录
WORKDIR /app
# 将本地的app.jar文件复制到容器中
COPY app.jar /app/app.jar
# 暴露服务端口
EXPOSE 8080
# 定义容器启动命令
CMD ["java", "-jar", "app.jar"] 记得指定启动参数的端口!
compose
version: '3'
services:
eureka-server:
image: your-eureka-image
ports:
- "8761:8761"
networks:
- my-network
product-service-1:
build:
context: ./product_service
dockerfile: Dockerfile
ports:
- "8081:8080"
environment:
- PORT=8080
- EUREKA_SERVER_URL=http://eureka-server:8761/eureka/
networks:
- my-network
product-service-2:
build:
context: ./product_service
dockerfile: Dockerfile
ports:
- "8082:8080"
environment:
- PORT=8080
- EUREKA_SERVER_URL=http://eureka-server:8761/eureka/
networks:
- my-network
networks:
my-network:
driver: bridge
其余地方可以参考黑马的视频运行 gatling 的命令: .\mvnw gatling:test
加了个模拟负载的 workload(加了等于白加)
其实不加 workload 也不快
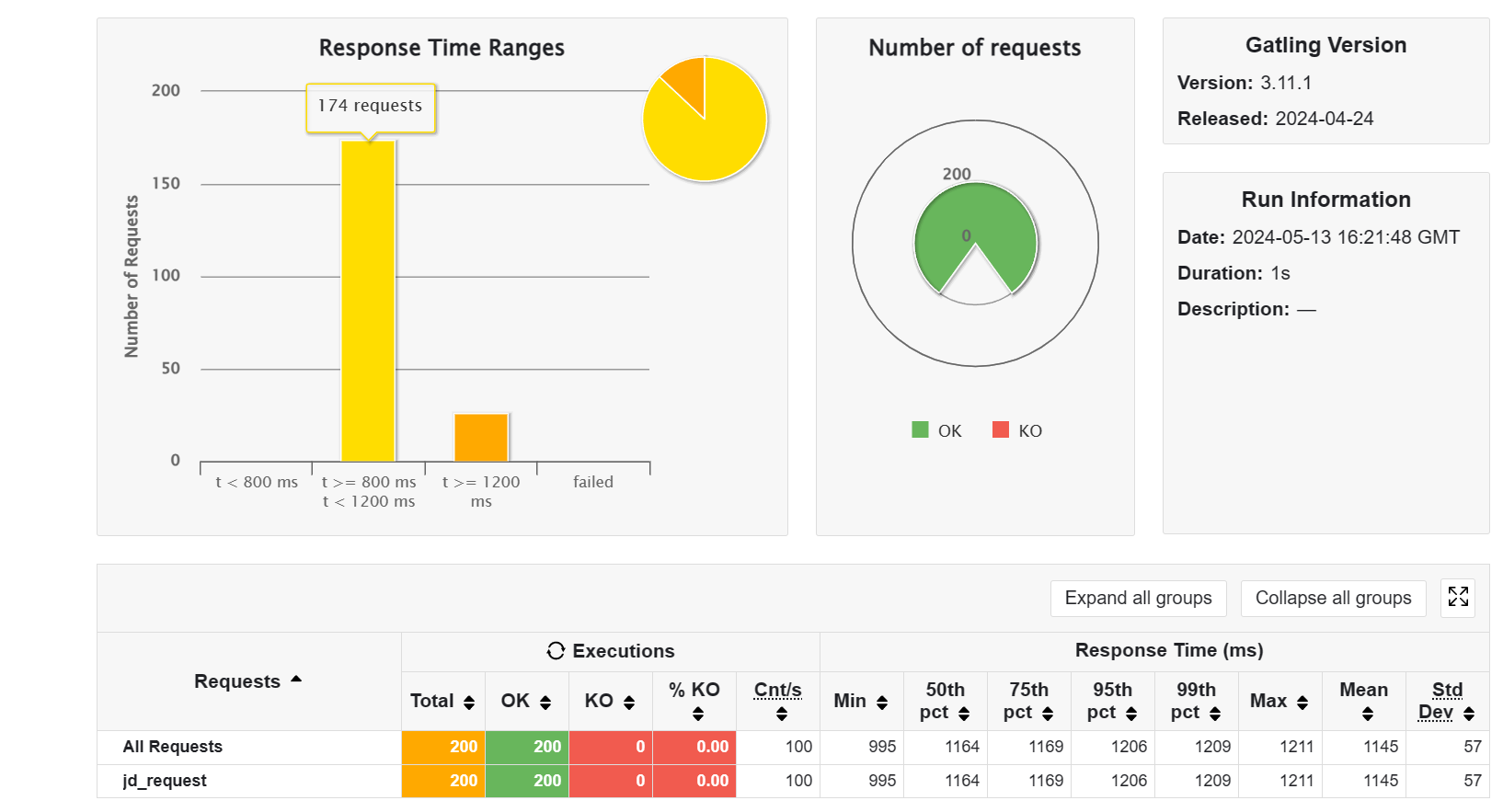
在不加 workload 的情况下,开启测试,开启三个 product 服务,还真就变快了(可以看到三个终端都有输出 sql 语句,表明请求确实落到了不同的端口上)
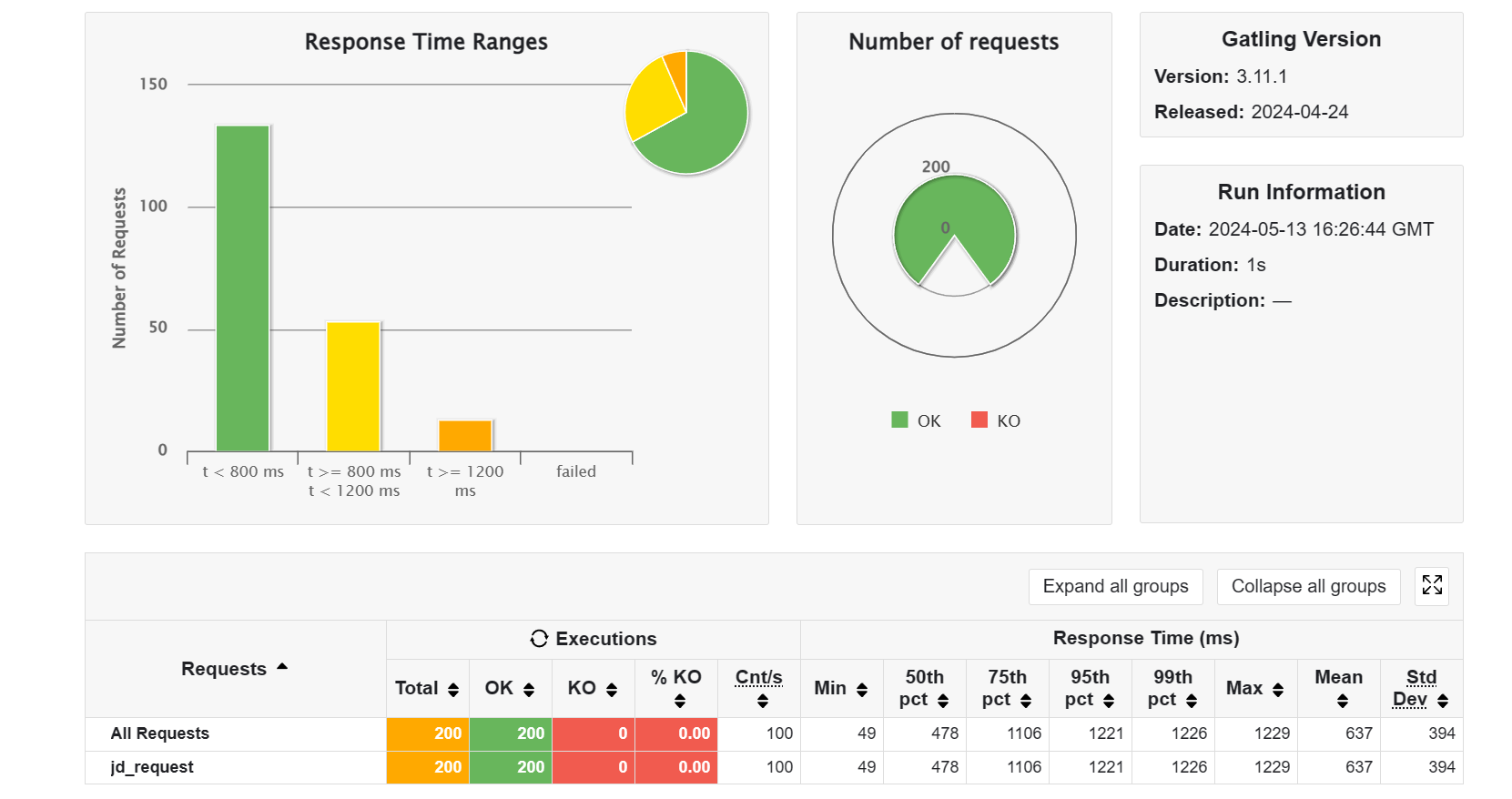
(以上只测试 get 请求的效果)
啊,为什么开启服务后直接 gatling 测会 fail,用浏览器访问一次后再测就 ok?
现在直接把 workload 加到 1e10(本地计算一次 workload 用时在 1900ms 左右),预期效果是单个服务如果访问量达到上限,就需要做 workload,导致用时很长,测试结果是符合预期的
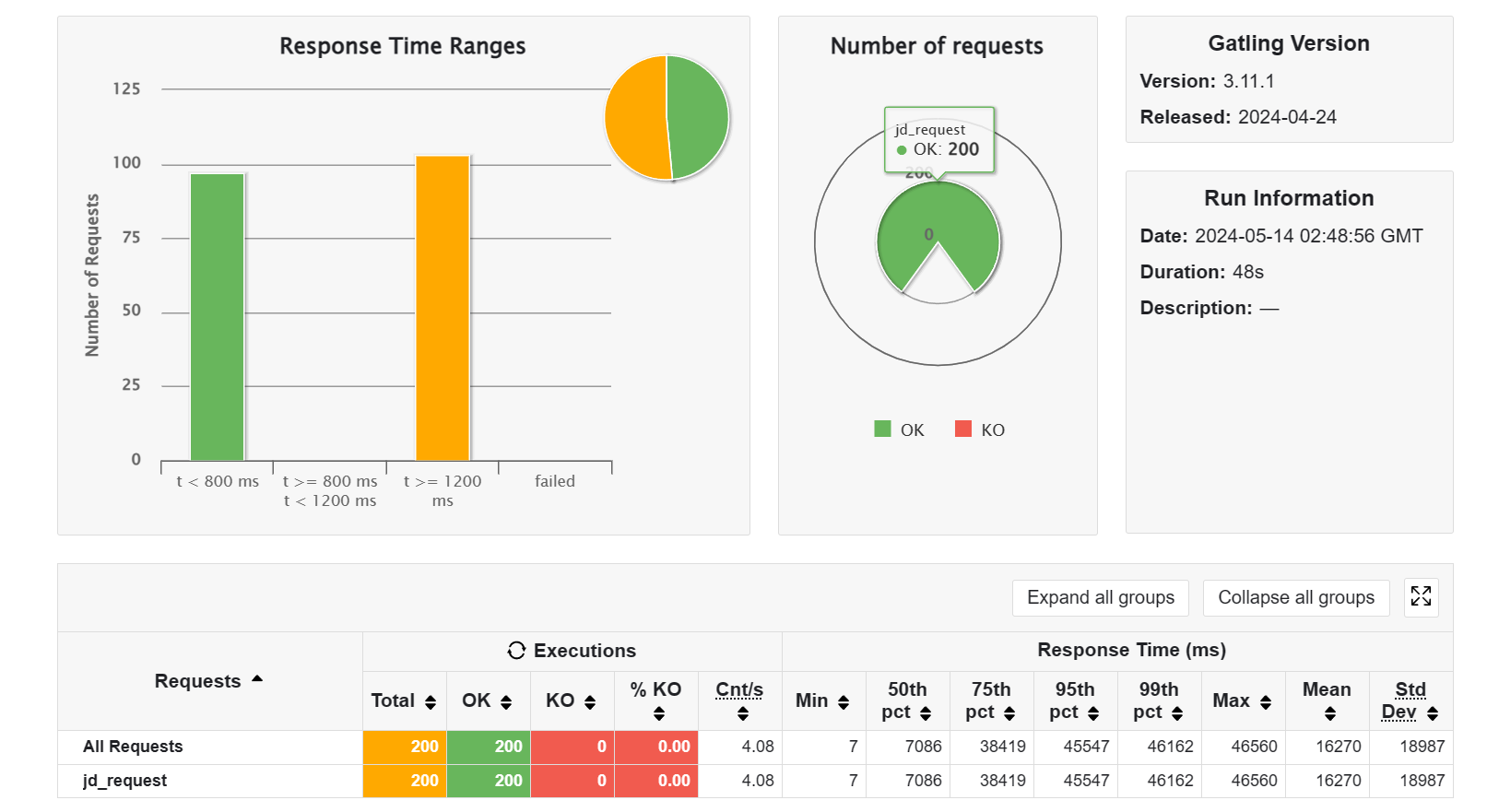
好,然后开启负载均衡,开启三个实例,效果也是符合预期的,因为单个服务不容易达到上限了,所以有很多访问是可以迅速响应的

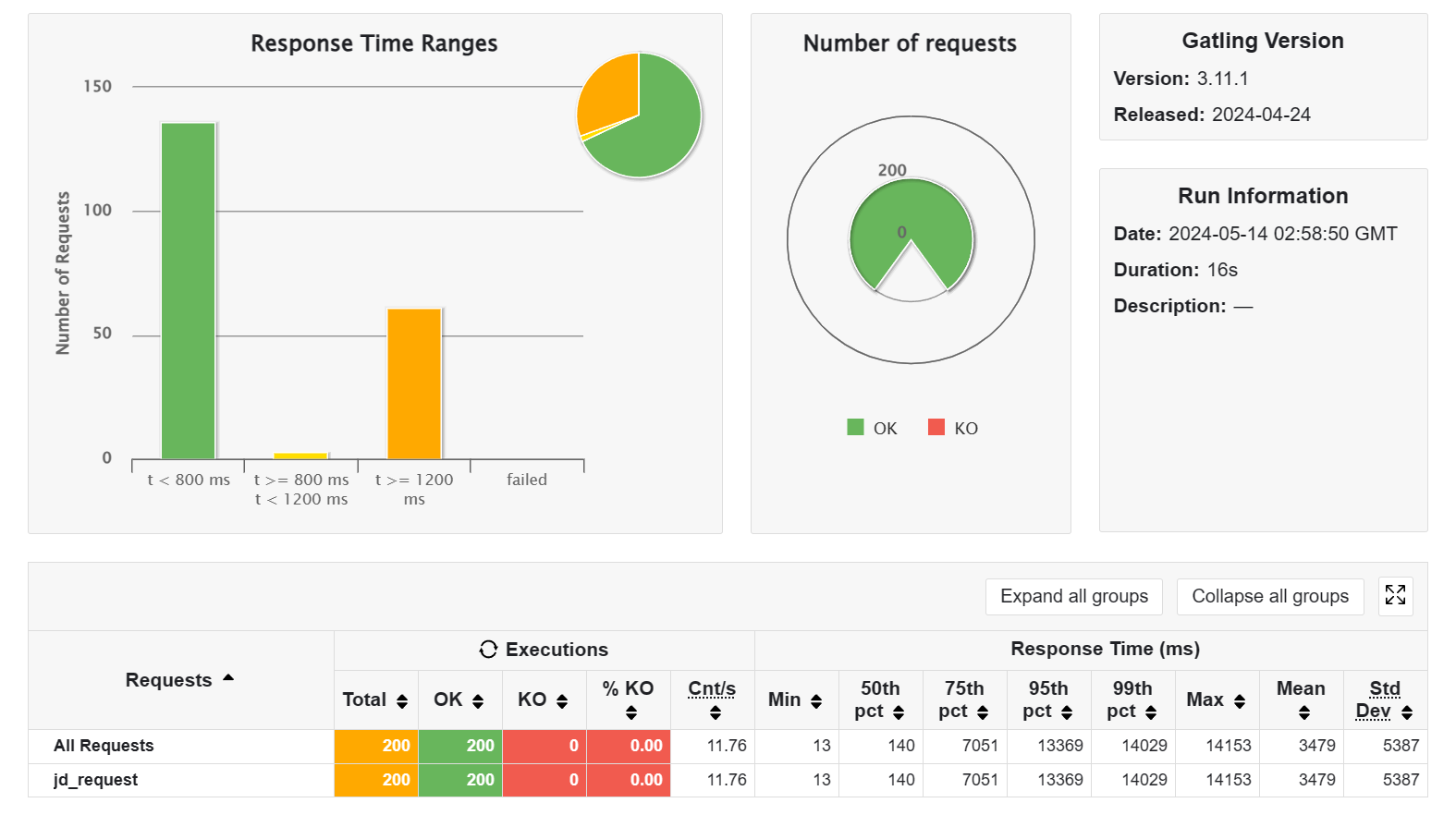
CAUTION
TODO:在 docker 上部署项目
TODO:目前是无法保证不同服务处于同一个事务间,导致数据库的写锁不起作用的,需要引入分布式事务(seata)
aw07(🔗)
Spring batch:job 分为 steps,用 repository 保存执行过程的部分结果
Guide 仓库:https://github.com/spring-guides/gs-batch-processing
这里的 listener 对象在类定义中被注释为 component,因此不需要 @bean
Chunk 的概念:指的是执行写事件时,等若干条数据完成后一起写入,因为每次写入数据库都需要开启事务,如果每条写都开启一个事务,就会导致耗时长。但是 chunk 也不能选得太大,假如发生错误,chunk 个数据都得重来(错误恢复机制),也是很耗时的
链条式 processors
Tasklet step:小任务组合
串行/条件分支的流式 step
并发流程:split flow,示例代码 https://github.com/sa-spring/spring-batch-split
怎么加负载:学学他的 Fibonacci
多线程执行 step:用 simpleAsyncTaskExecutor(但存在无限创建线程问题,要用线程池 ThreadPoolTaskExecutor)
Remote chunking(以后讲)
Partitioning:https://github.com/sa-spring/spring-batch-partition 数据分片
关于 TransactionManager 的知识,用于测试的话,resourceless 就可以,如果真的环境中要做进一步配置

关于是否要更新表,在 properties 中 spring.jpa.hibernate.ddl-auto 选择 update 或者 none(前者的效果是,初始化时会检查表是否存在,不存在则会创建 schema,存在则更新表结构)
用了 transactionmanager 后,加上 executor 会出现死锁!(后续实现好了就不会出现这个问题了)
为什么创建 varchar(10000) 之后数据库还是显示 varchar(255),这是因为数据库使用了 utf8mb4 编码,要换成 utf8 编码,默认最长是 65535?实际上不是,学习了一下字符集编码发现,如果要支持 emoji 的话,用 utf8mb4 是更好的选择,真正的原因看下面
很奇怪的事情是,实体类加上 @Table 注释之后,它创建表时并没有看我的 schema-all.sql,而是根据实体类的定义给我建了一张表,又因为我的的类型是 String,就默认它的类型是 varchar(255) 了
终于弄清楚了执行的流程
- 没必要使用 entity 和 table 注释,它们是为了 jpa 准备的,如果用了的话,jpa 就会自动建表
- 按照教程里用 jdbc 的话,初始化执行脚本的操作是:
spring.sql.init.schema-locations=schema-all.sql - 这次不想用 jpa 了,原因在于配置 jpawriter 时不是很清楚整个流程(虽说 jdbc 版本的也不清楚)
- Bufferreader 是线程不安全的,需要在 read 函数里面加锁,否则数据会被重复插入
配置一下云服务器和 mysql 服务
配置好之后,在 mysql workbench 中配好连接信息,再跑一下程序,就可以插入到云服务器的表中了,可以观察到,插入远程数据库和本地数据库,在用时上是慢很多的
下一个尝试是自定义 ItemWriter,尝试同时插入两张表,表 A 的主键值作为 表 B 的外键值,测试了下发现是可以对得上的
设置了下 jvm 参数,-Xmx4g,-Xms2g
测试 100 项记录的插入,在检查 url 的情况下,执行情况
取消对 url 的检查,执行情况
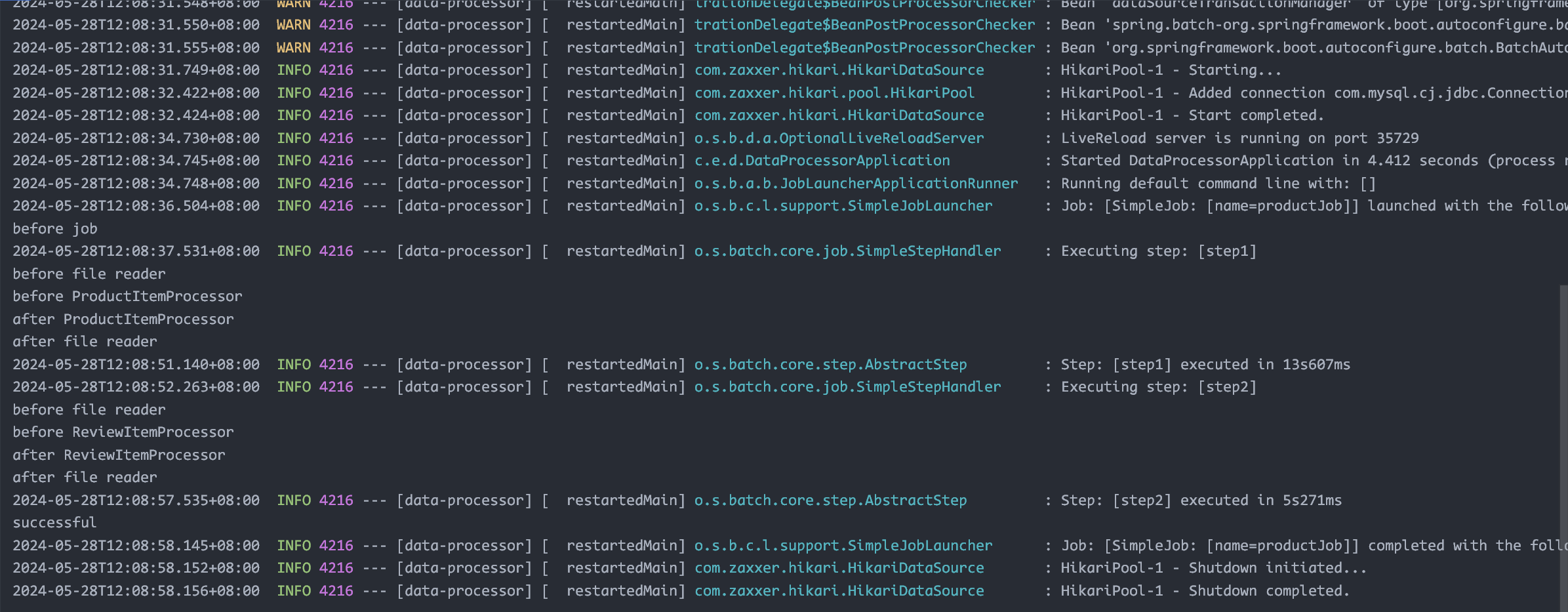
改成用 split flow 并发执行,step 内部串行
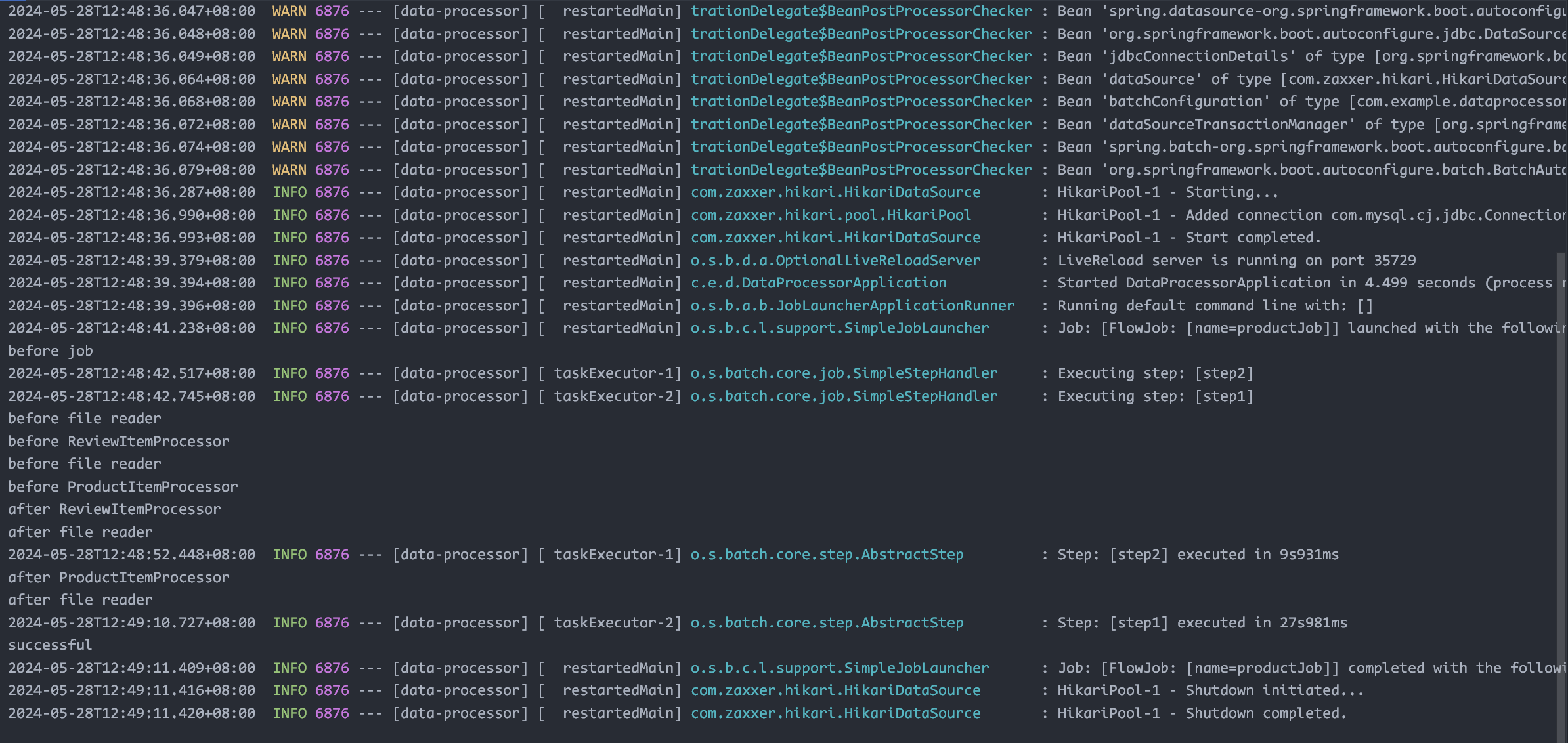
改成 split flow 和 step 都并发
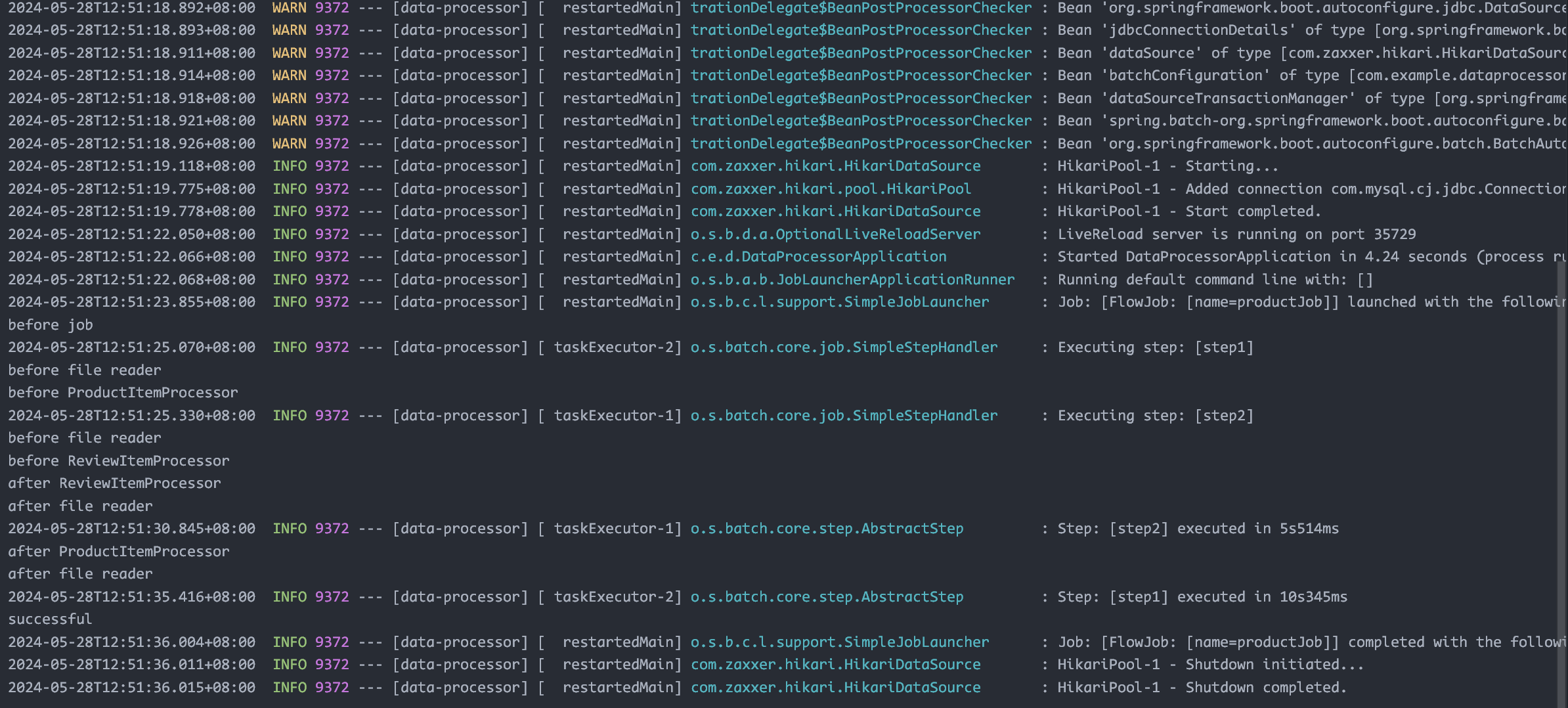
这次改成每个 json 只处理一张图片,多加了两个 flow 用于单独处理 url 测试,速度就快很多
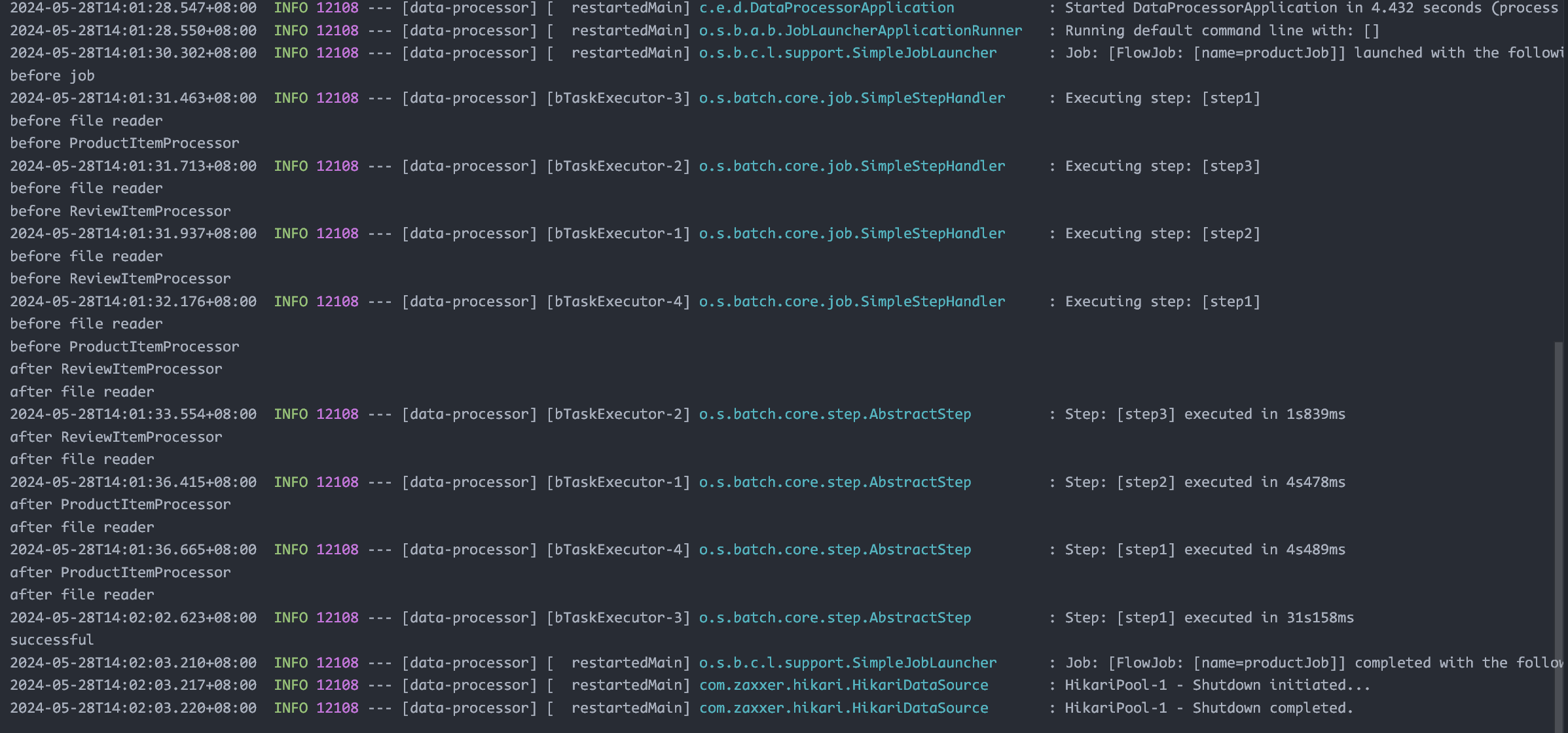
讲讲为什么把测试 url 单独拿出去执行:原本的处理逻辑是插入数据库前先判断 url 是否正常,不正常就不插入,但是这样会在一个事务中又操作数据库又发送 http 请求,速度很慢。考虑到异常的 url 只有少数,不妨先无脑插入,再通过额外检查来建立一个 bad_url 的表,它的记录会很少,最后在查数据库的时候取出 url 后查一下这个小的表判断是不是 bad_url 即可,这样的话就可以保证效率了
试改成用 jsonreader,需要先将 jsonl 转成 json 数组,参考工具:https://jqlang.github.io/jq/,命令为 jq -s '.' input.jsonl > output.json,这个工具虽然不错,但还是存在问题:原来的数据中存在转义字符,jq 会在转换过程中读取这些字符,最后输出为 utf-16 格式,jsonreader 读取就会出问题。最后是通过写一个 python 程序来帮我转换成 json 数组,这样就不会出问题,但如果面对大文件,python 程序可能爆内存,这个时候就需要考虑把原来的大文件拆分成多个小文件再处理了,这件事情也可以交给 python 解决
库中提供的普通 reader 是线程不安全的,考虑用 SynchronizedItemStreamReader 进行封装(看文档看到的)
又出现新的问题:在执行长任务时,数据库连接池超时关闭连接,这个跟 hikari.maxLifetime 有关,见 https://stackoverflow.com/questions/60301008,然后查看 hikari 的 giuhub 的 readme

更多的讨论见 https://github.com/brettwooldridge/HikariCP,https://ayonel.github.io/2020/08/18/hikari-keeplive/
我把它设置为 spring.datasource.hikari.maxLifetime=60000,就没有遇到这个问题,但是 mysql 的 wait_timeout 是 28800,即 8 小时,明显是大于默认值 30min 的。我只能推测是网络设施的某个生存时间小于 30min
这个运行时间也太慢了吧

是否存在线程安全问题呢?
测试一:4608、4858、4751、65

更新:也就是说,换成普通的 reader 和 writer,在执行耗时上更优一些,查询行数发现也是 5000

测试二:4721、5058、4477、65

什么鬼啊,table inspector 显示的 rows 数跟实际选出来的不一样的?
看来还是以实际 select 出来的行数为准,实际得到的行数是 5000,是线程安全的
现在改用普通版的 reader 和 writer
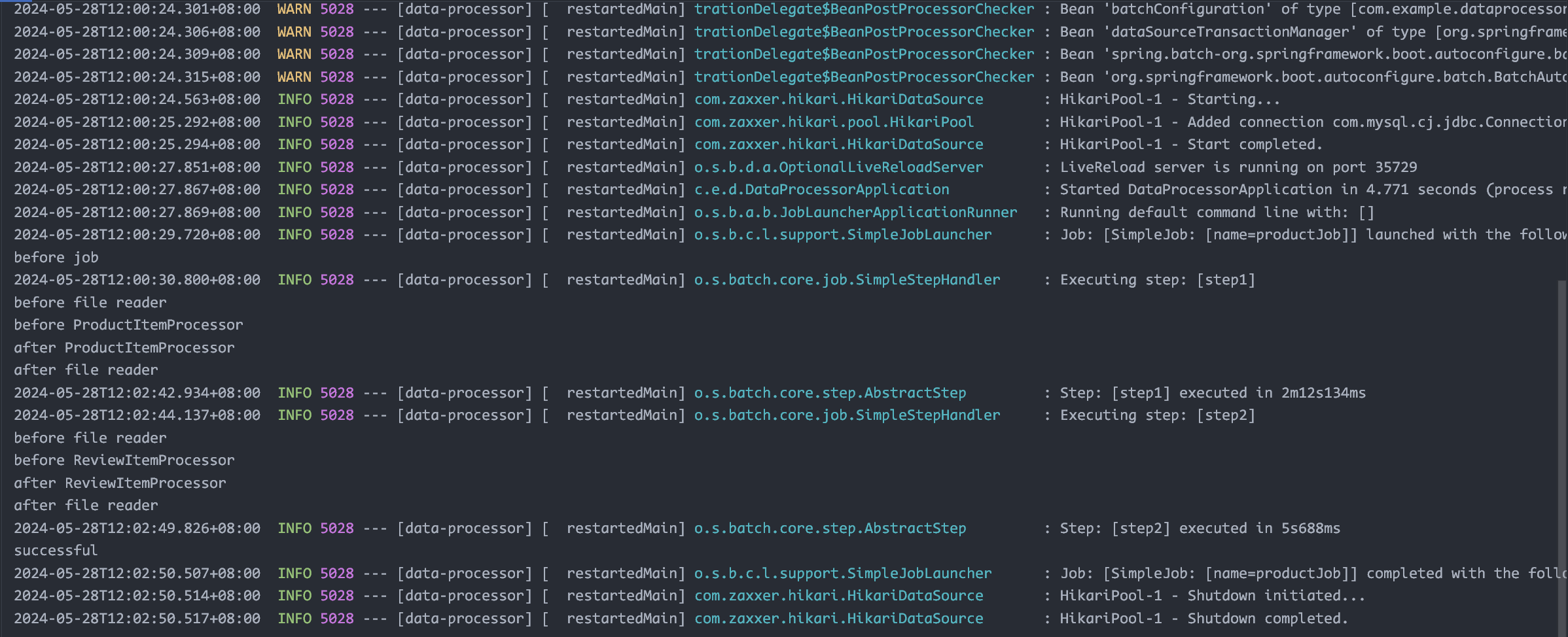
加入日志模块,看看一共创建了哪些线程,然后发现只创建了两个线程,一个 taskExecutor 创建一个线程,这就很奇怪了
然后考虑到 job 和 step 都用的同一个 subTaskExecutor,看不出来是谁创建的,然后就把 job 的换成 mainTaskExecutor,然后就出现运行时各种奇怪的读取文件出异常?考虑是不是线程安全出了问题!但是为什么原来那样用同一个 subTaskExecutor 就不出问题呢?因为是加了 bean 注释的,它们在共享同一个线程池!改回了线程安全的 reader 和 writer,就正常执行了
现在 job 用 sub 执行器,step 用 main 执行器,发现 writer 基本是在被 main 调度,sub 只在 Executing step: [step1] 和 Step: [step1] executed in 时有输出,也就是说 job 这个配置只是创建两个线程分别执行 step1 和 step2?
接下来尝试把线程安全的 writer 改成普通的 writer,发现速度快了很多(2k 行数据,线程安全版的是 4min)

也可以观察到 writer 被多个线程所调用,也就符合预期了。所以就是要自己保证 reader 和 writer 的线程安全性,例如不使用 cursor based 的 reader(我使用的 JsonItemReader 是线程不安全的,所以需要封装),writer 的话在我的这个应用中不涉及共享数据,所以是 ok 的
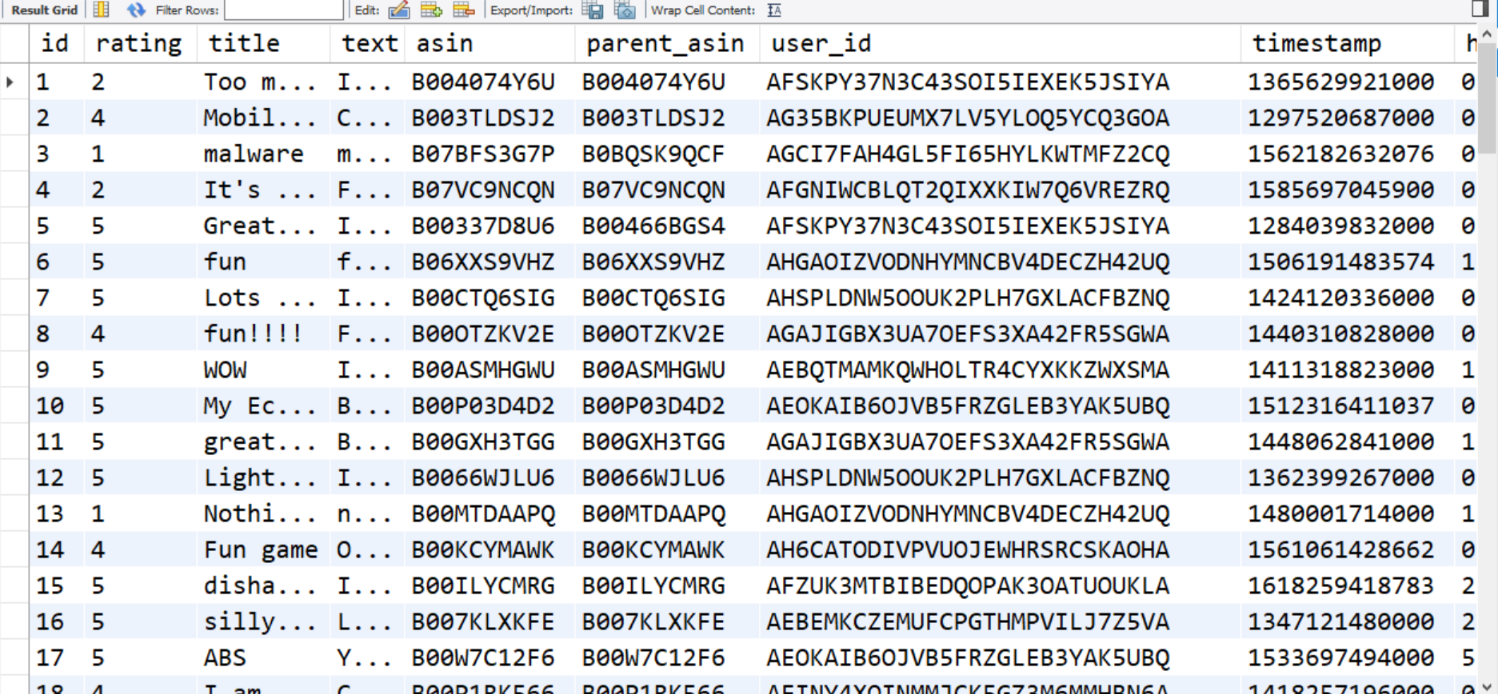
测试用的数据集:meta 70537,review 130434
在最终的配置下(batch=100),运行速度比之前提高了非常多

查数据库的行数:meta 70537,review 130434,正确!
换成 batch=500 试试,提升不大,看来瓶颈还是在 reader 那里

那就把数据进行分片吧,还是 batch=500,但是这次每个文件最多 30000 行,一共分出 8 个文件,快了一倍多
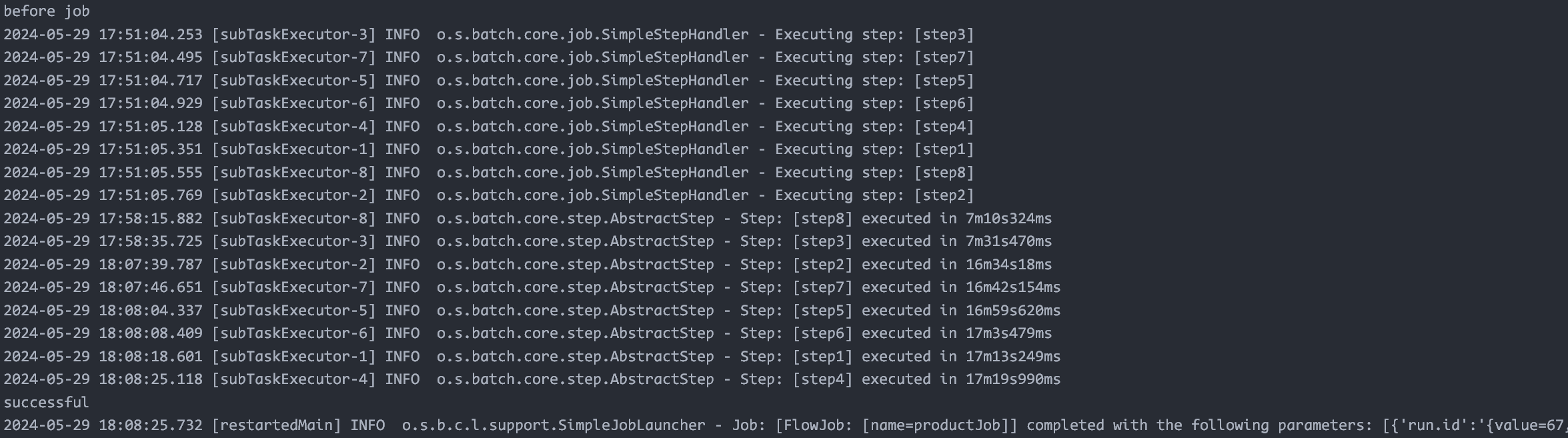
同样的配置,把核心线程数调大之后反而变慢了,应该是超过了我机器的核心数了
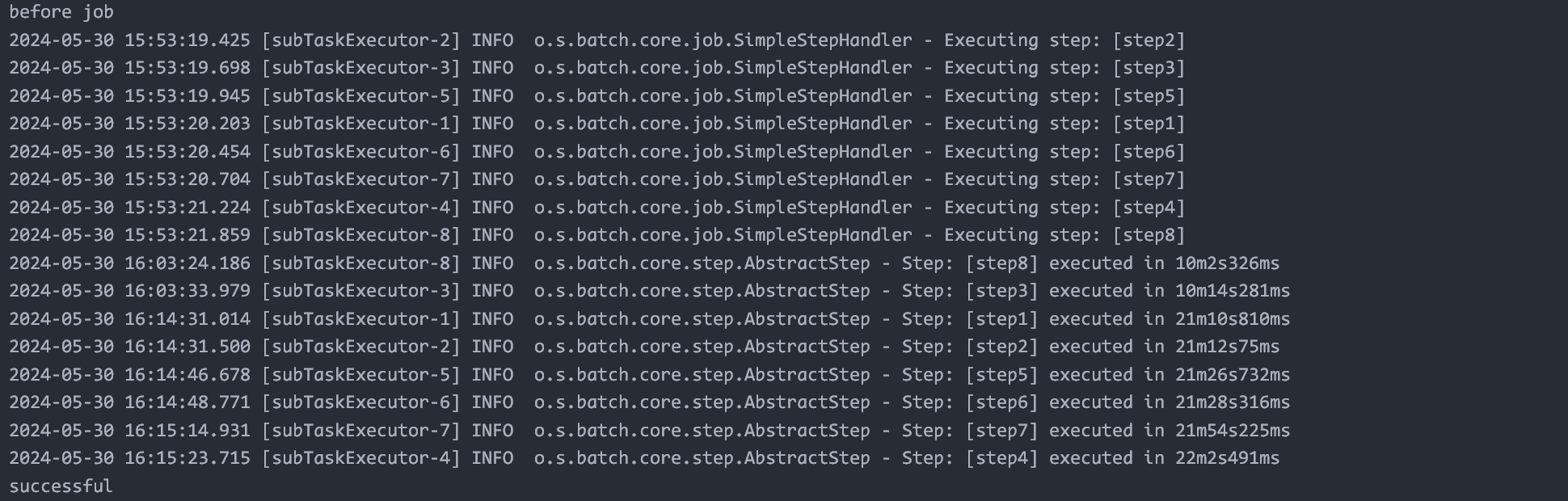
用 partitioner 实现一次,发现 slavestep 不加线程池,快 20min 只完成了一个子任务,太慢了吧,内部在串行执行吗?

即使加上线程池,还是很慢呀,是配置出了问题吗

仅仅是把线程池的核心线程数变为 16,会多分配 8 线程(读 + 写线程会打满 16 个),然后速度就提升得飞快

观察日志又发现,reader 线程数=文件数,processor 和 write 在同一个线程中执行,这是什么原因呢。通过运行 spring-batch 的 demo 发现,reader、processor、writer 都只是创建了一个实例,并发调度的是 read()、process() 和 write() 方法
下面尝试 55w 数据的插入,看来时间跟数据量不是一个线性的关系

aw08(🔗)
Observer 观察者模式:java gui
Pub-sub 发布订阅模式:guava https://github.com/sa-spring/guava-eventbus
- 由事件管理器进行管理,异步通信,解耦
Spring 的标准事件:https://github.com/sa-spring/spring-events
Event channel 才是最复杂的组件,尤其是分布式环境下,消息中间件 mom
AQMP:消息中间件的应用层协议 https://github.com/sa-spring/spring-amqp
- 生产者产生消息,交给 exchange,根据 binding 交到某个队列,消费者取消息来处理
启动 rabbitmq docker:docker run -d -p 5672:5672 -p 15672:15672 --name rabbit rabbitmq
启动后需要进入容器内部:docker exec -it 容器 id /bin/bash
开启管理界面:rabbitmq-plugins enable rabbitmq_management
web 界面信息显示不完全:先 cd /etc/rabbitmq/conf.d/,然后 echo management_agent.disable_metrics_collector = false > 20-management_agent.disable_metrics_collector.conf
这样就可以在本地访问 15672 端口了
Work Queues:让多个消费者绑定到一个队列,共同消费队列的信息
- 同一消息只能被一个消费者消费
- 多消费者:解决消息堆积问题,通过配置 preFetch 参数实现能者多劳
三种交换机
- builder 和 new 的区别:前者是建造者模式
基于注解来创建比较方便(RabbitListener)
Jdk 的序列化是不推荐的(安全性差,体积大)
应用集成
用基于消息的事件驱动架构,是常用有效的系统设计方式
demo:https://github.com/sa-spring/spring-integration
aw09(🔗)
- 通过线程 sleep 来延迟,阻塞式任务,就需要新建线程来处理下一个任务,开销很大
- 异步执行,通过回调函数的形式,让一个线程能够做别的事情,但是引起 callback hell,代码可读性变差
改进:响应式流,类似 publisher 和 subscriber
背压控制:一方给反馈,另一方调节速率
Mono:0 或 1 的数据
Flux:0 - N 的数据
异步编程的代码是命令式的,而响应式编程是声明式的
Spring web flux:
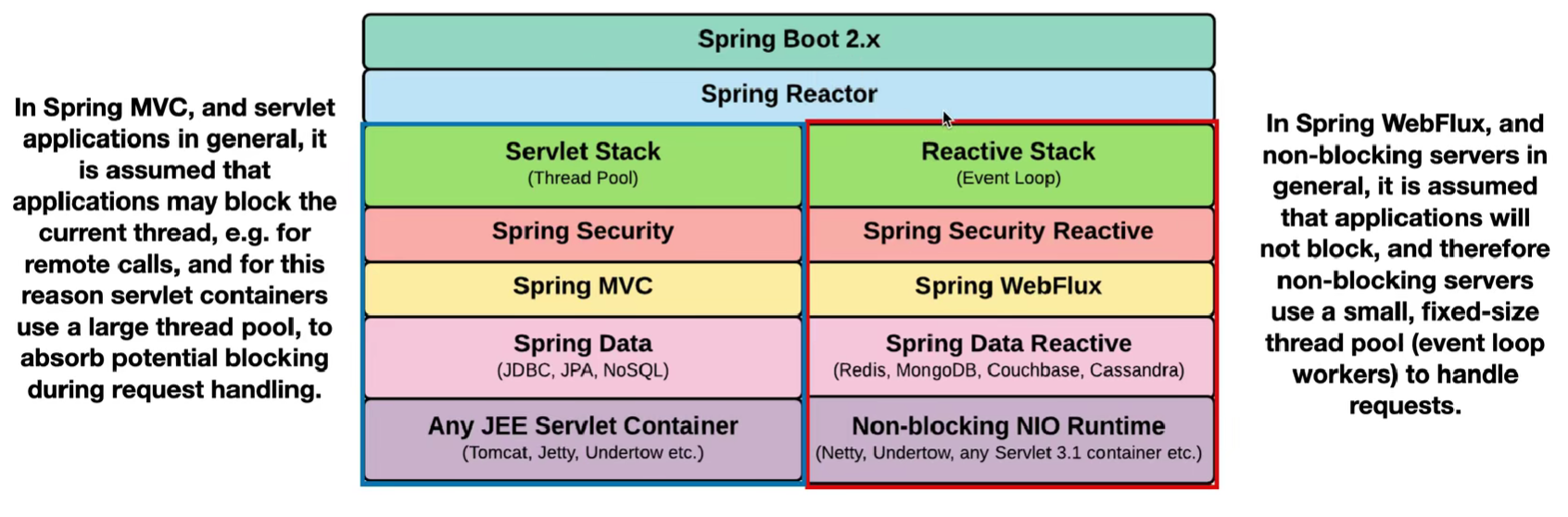
一个 demo:https://github.com/sa-spring/employee-reactive
什么是响应式系统:https://www.reactivemanifesto.org/
TODO:协程和 reactor 的区别,tomcat 和 netty
Webflux 向下兼容 mvc 的大部分注解
sse:server send event 服务端事件推送
视频教程:https://www.bilibili.com/video/BV1sC4y1K7ET
评论区说到 jdk21 的虚拟线程比 webflux 好 虚拟线程类似于 go 的协程 fork-join 思想:分治,类似 map-reduce
可以在配置文件中指定启动时执行的初始化 sql 脚本(与 r2dbc 不冲突)
关于 map 和 flatMap:https://medium.com/@salvipriya97/java-stream-api-when-to-use-map-and-flatmap-1dd19e37ff73
关于 eureka 服务名调用的配置:https://github.com/spring-cloud/spring-cloud-netflix/issues/4269
关于启动时 loadbalancer 报 warning,需要更新 cloud 版本为 4.1.1,见 https://github.com/spring-cloud/spring-cloud-commons/issues/1315
PO 层:持久层对象,有点像是我使用的 model 层(在 mvc 架构中)
DAO 层:跟 service 的功能差不多,用在 mybatis 中比较清晰
见一个仓库:https://github.com/pikaMonkey/Java-Week
Spring 依赖注入:@Autowired 和 @Resource:https://www.bilibili.com/video/BV1jx4y1e7aL
spring gateway 要拦截的话需要配 GlobalFilter,而 webflux 的拦截器是 WebFilter,要实现鉴权的话,就不整成 webflux 的吧(鉴权这块做得完整的话挺复杂的)
参考代码(webflux+jwt):https://github.com/ffzs/Webflux_Jwt
参考文章(spring+jwt):https://mp.weixin.qq.com/s/WbuyObjPYBezA0IsekQfjw
引入 redis,要考虑 k-v 怎么设计,通用做法是 key 设置成 String,但这样就产生一些问题,例如 getAll 缓存了全部数据,findById 的时候,某一项又会被单独缓存,某一项被更新了,又要手动令不同的缓存都失效,频繁调用序列化和反序列化,又会导致性能开销变大
引入 redis 之后,分布式事务怎么做,一致性怎么保证,事务回滚怎么办
Dubbo+SEATA 框架,但似乎不支持 webflux 和 r2dbc 这块,寄
疑问区
如果是以注释的形式加断路器,可以指定配置吗,断路器的 name 属性有什么用呢(异步调用,断路器没用了啊)
继续通过配置类实现
import io.github.resilience4j.circuitbreaker.CircuitBreakerConfig; import org.springframework.cloud.circuitbreaker.resilience4j.Resilience4JCircuitBreakerFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class CircuitBreakerConfig { @Bean public CustomCircuitBreakerCustomizer customCircuitBreakerCustomizer() { return new CustomCircuitBreakerCustomizer(); } public static class CustomCircuitBreakerCustomizer implements CircuitBreakerCustomizer { @Override public void customize(Resilience4JCircuitBreakerFactory factory) { factory.configure(builder -> builder .timeLimiterConfig(TimeLimiterConfig.custom() .timeoutDuration(Duration.ofSeconds(2)) .build()) .circuitBreakerConfig(CircuitBreakerConfig.custom() .failureRateThreshold(50) .slidingWindow(10, 5, CircuitBreakerConfig.SlidingWindowType.COUNT_BASED) .build()) .build(), "placeOrder"); } } }Transactional 自调用问题,不能在非 Tr 的函数体内调用一个 Tr 方法,只有外部过来的才行
gpt 说 webflux 默认用 jackson 库来序列化,因此取消了序列化接口,可以正常运行
测试环节:
Gatling 脚本:
class GatlingTestSimulation extends Simulation {
val httpProtocol = http
.baseUrl("http://localhost:8080")
.acceptHeader("text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.doNotTrackHeader("1")
.acceptLanguageHeader("en-US,en;q=0.5")
.acceptEncodingHeader("gzip, deflate")
.userAgentHeader("Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20100101 Firefox/16.0")
val feeder = Iterator.continually(Map("pg" -> (scala.util.Random.nextInt(50000))))
val scn = scenario("Testing webpos")
.feed(feeder)
.exec(
http("request")
.get("/products?page=#{pg}")
)
setUp(
scn.inject(
rampUsers(300) during (3 seconds) // 设置并发用户数和持续时间
).protocols(httpProtocol)
)
}不带 redis 缓存的情况下
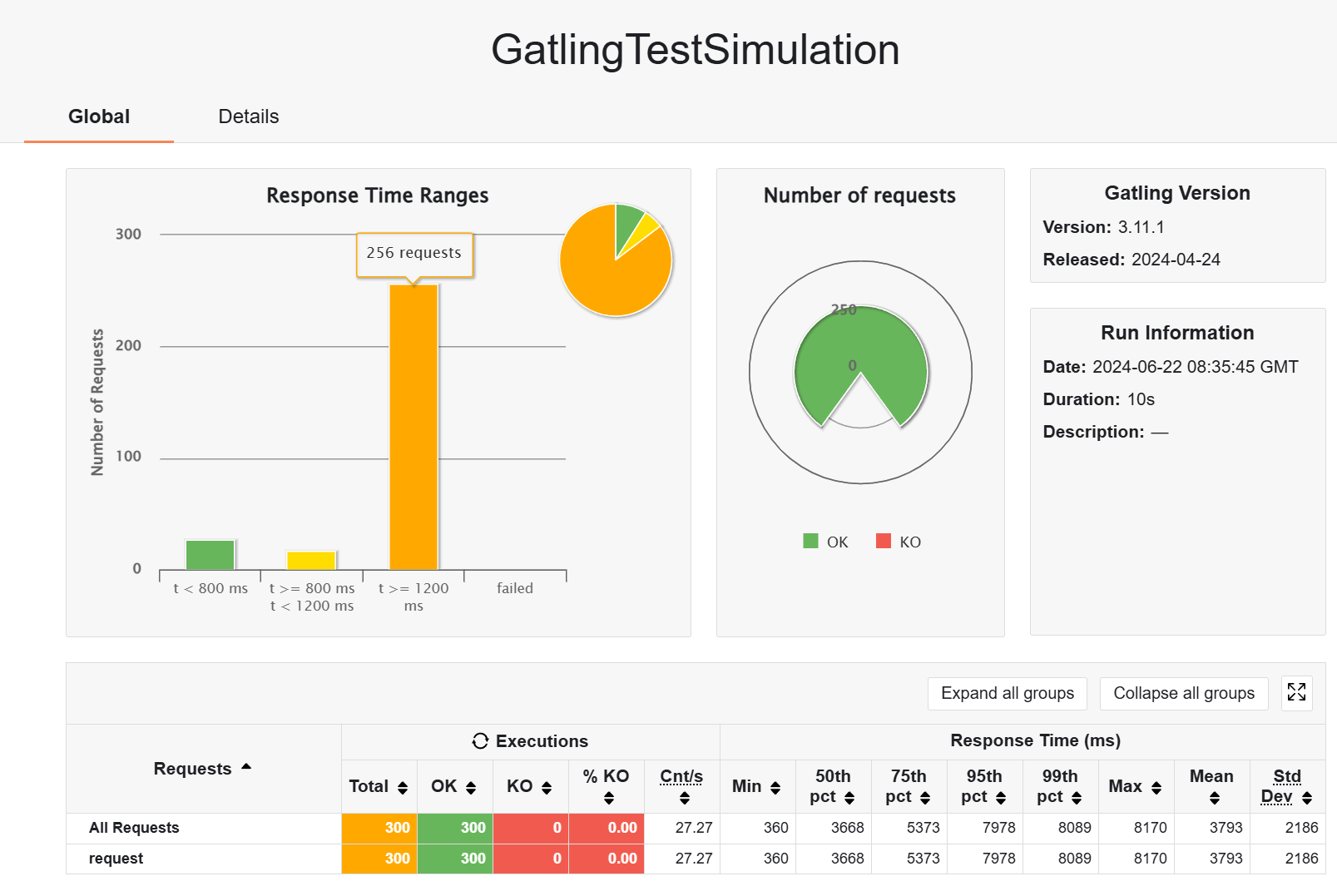
带 redis 缓存试试,发现都变慢了,为什么:用户随机访问一页,get keys 发现有 298 项,意味着缓存基本不命中,因此白白增加了数据转换的开销
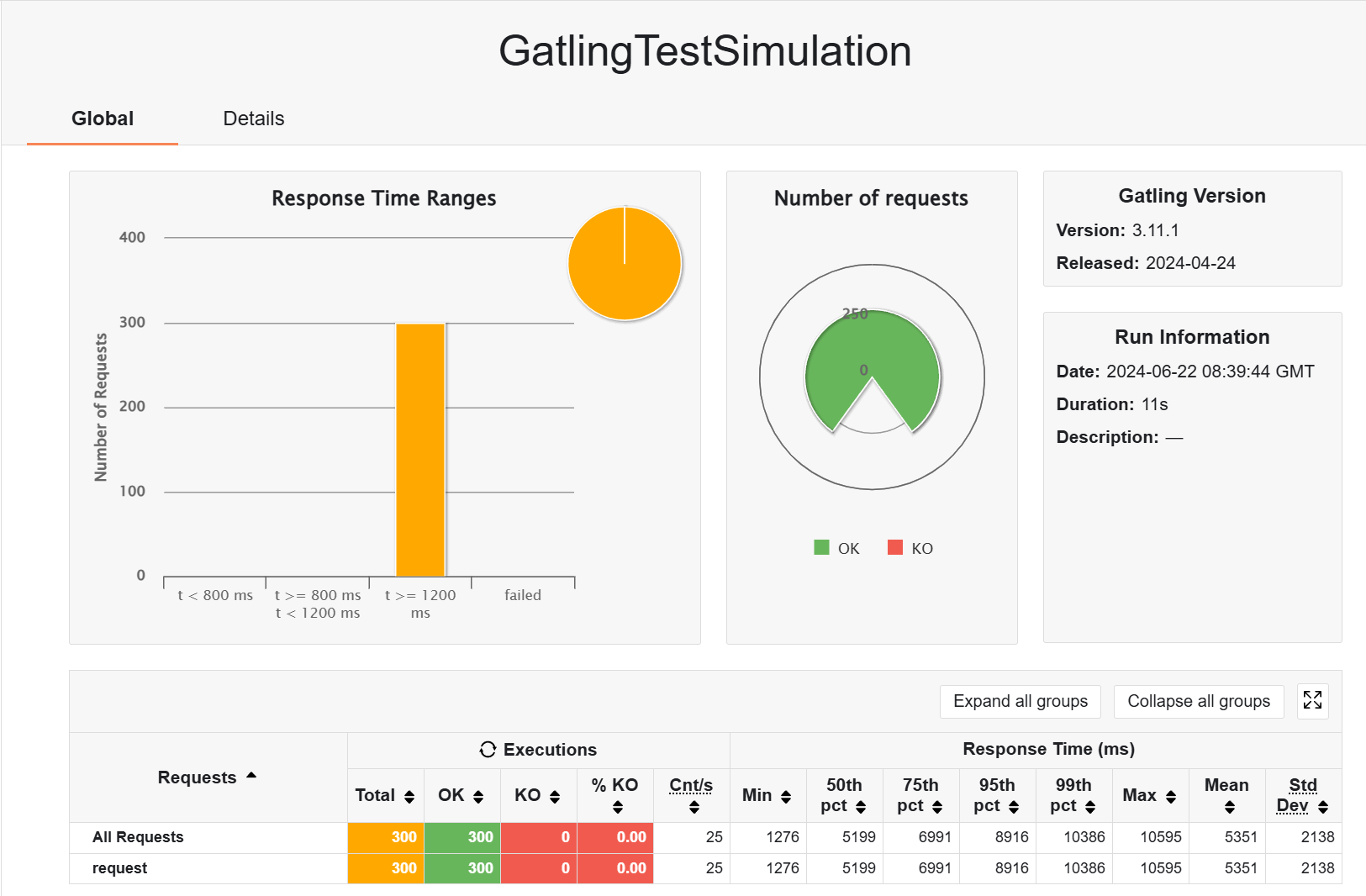
接下来,模拟访问 1-300 页,不带 redis 缓存
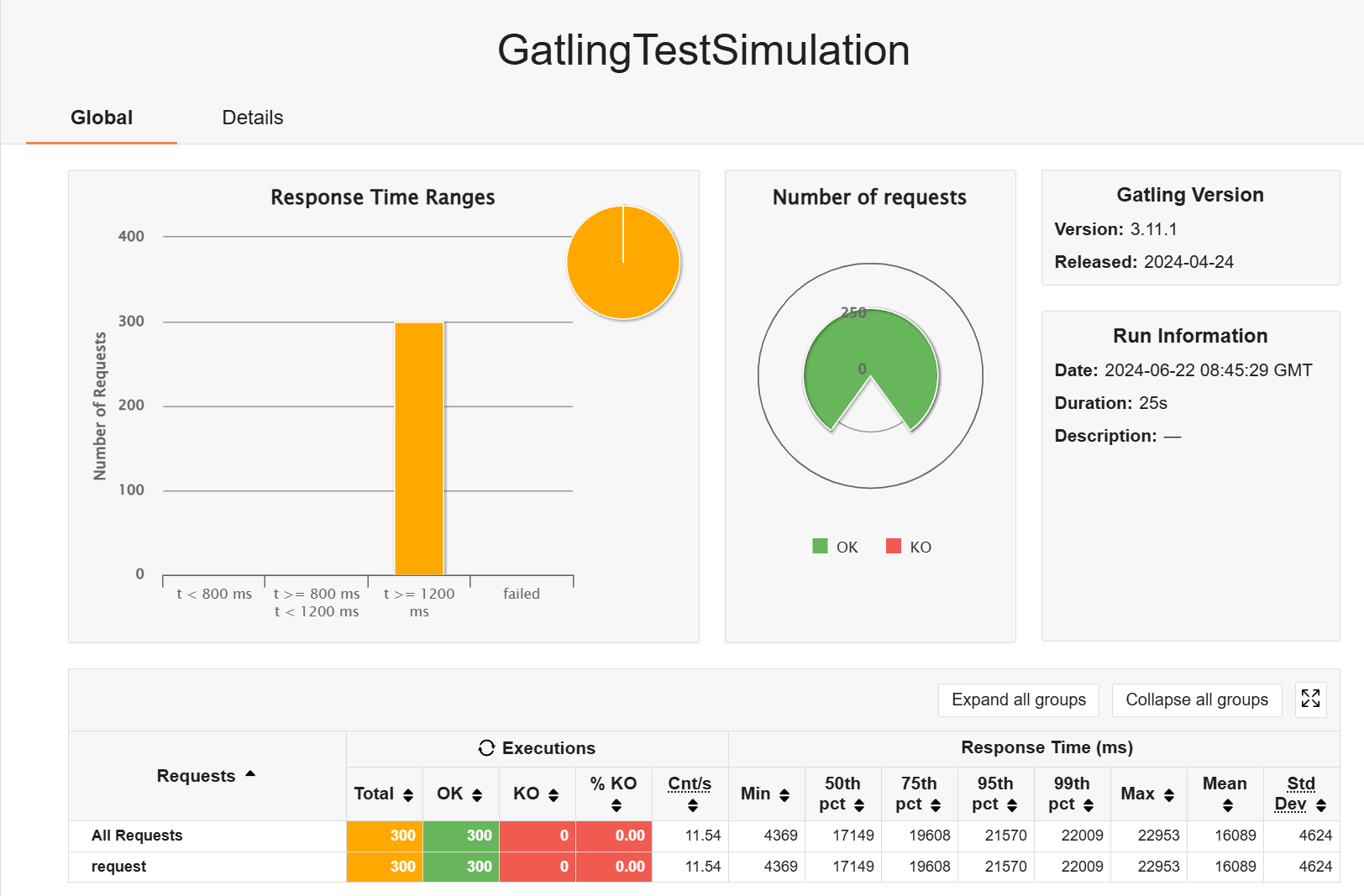
然后用 redis 预热一次,然后测试带缓存的访问,可以看到预热好后 keys 有 300 条,在访问过程中也可以发现有一些请求变快了,猜测这里的原因是 redis 也放在云服务器而不是本地,所以中途多了网络传输缓存的开销
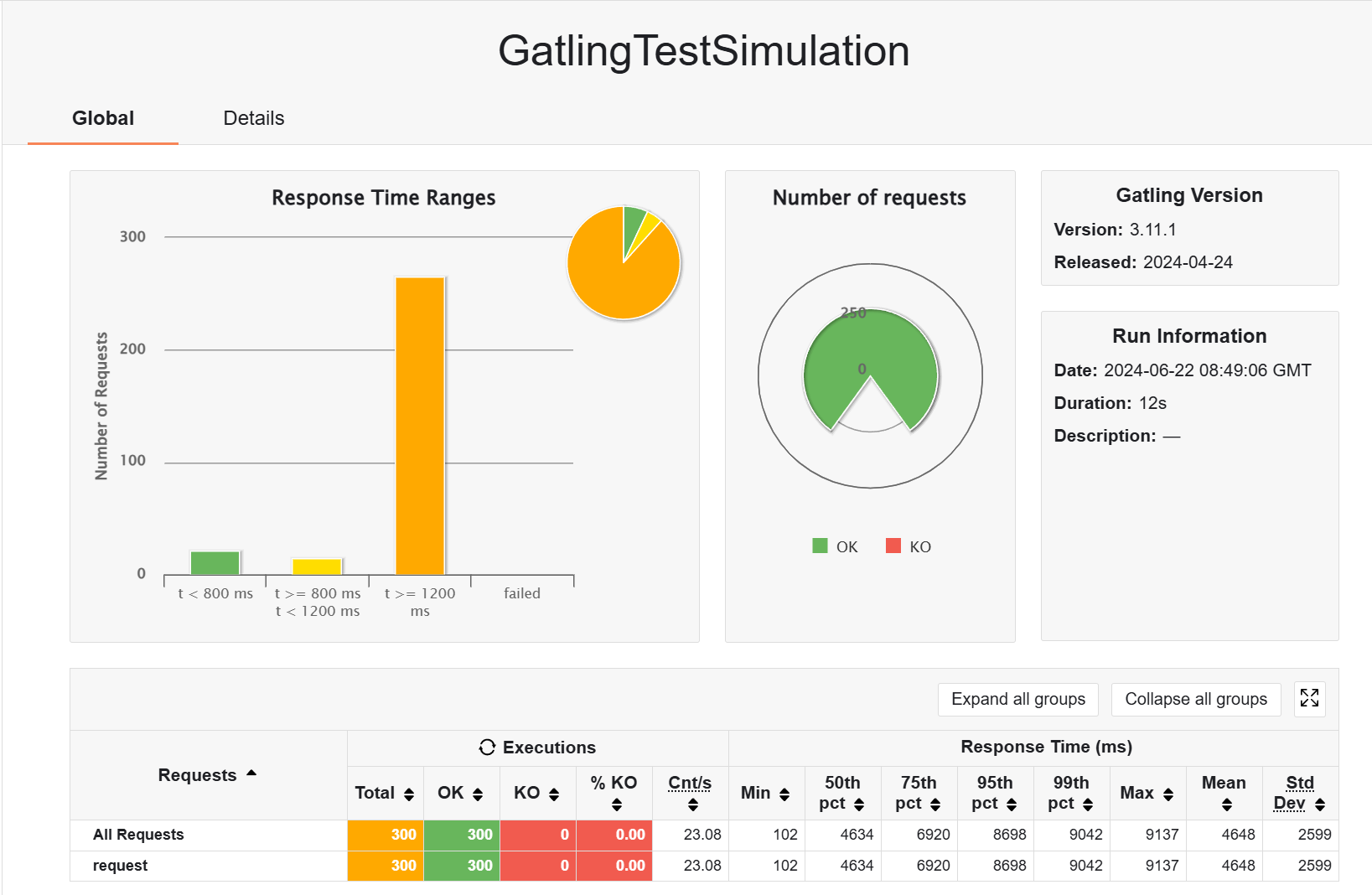
接下来我在本地开启 redis,同样做预热,然后测试,但是性能并没有什么区别啊,是我 redis 序列化配置得太烂了?暂时没弄懂

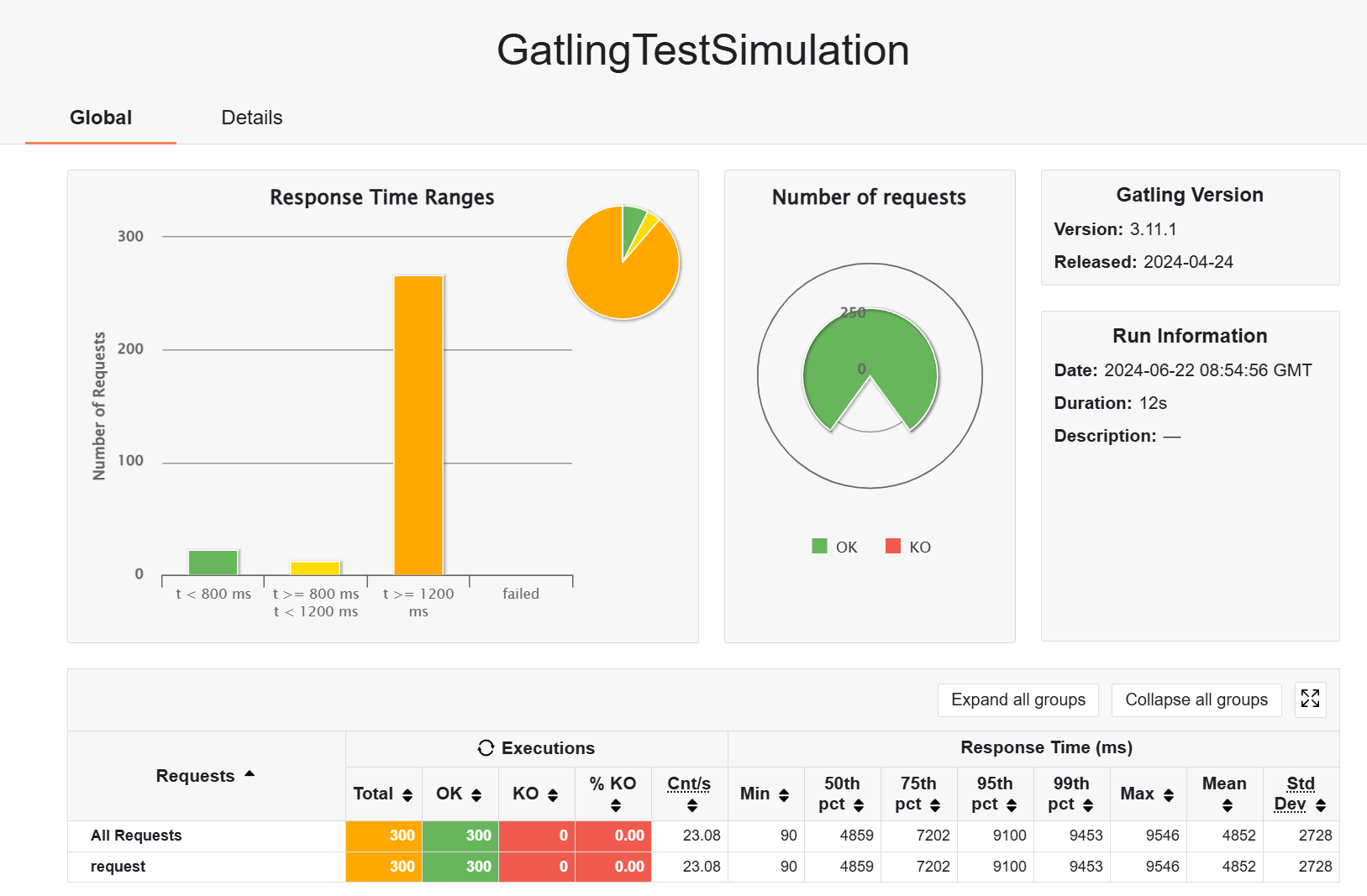
尝试把用户数降下来,200 个用户,5s,同样预热后测试
假如不加 redis 缓存,并没有体现出缓存的优势所在
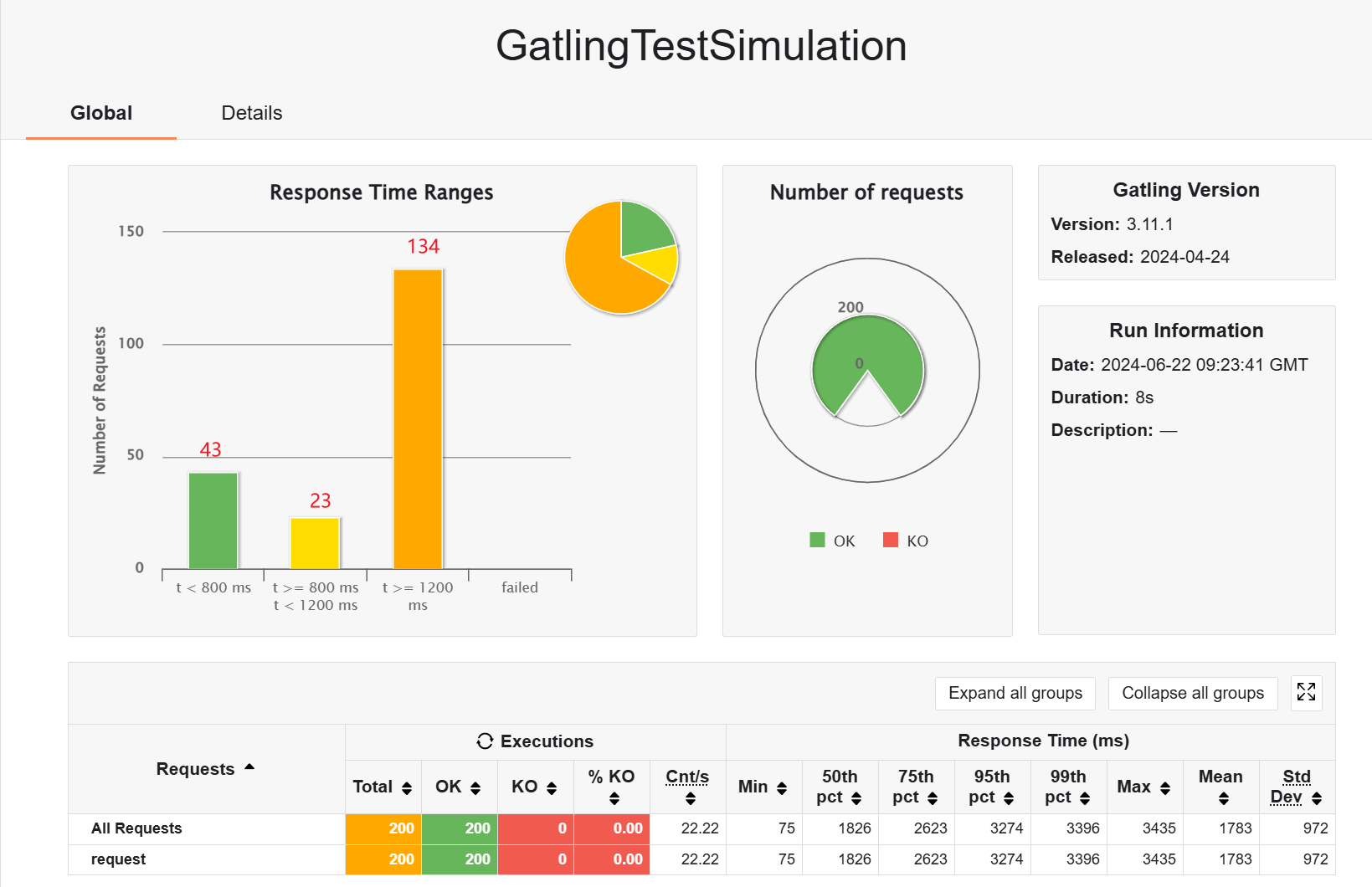
额,发现搞错了一点,我只对 product 加了 redis,但是返回 productDto 的时候,还有一个查表操作,这里没加 redis,现在加上,然后重新开始测试
不加缓存,200 用户,3s,测取单个 product 的数据
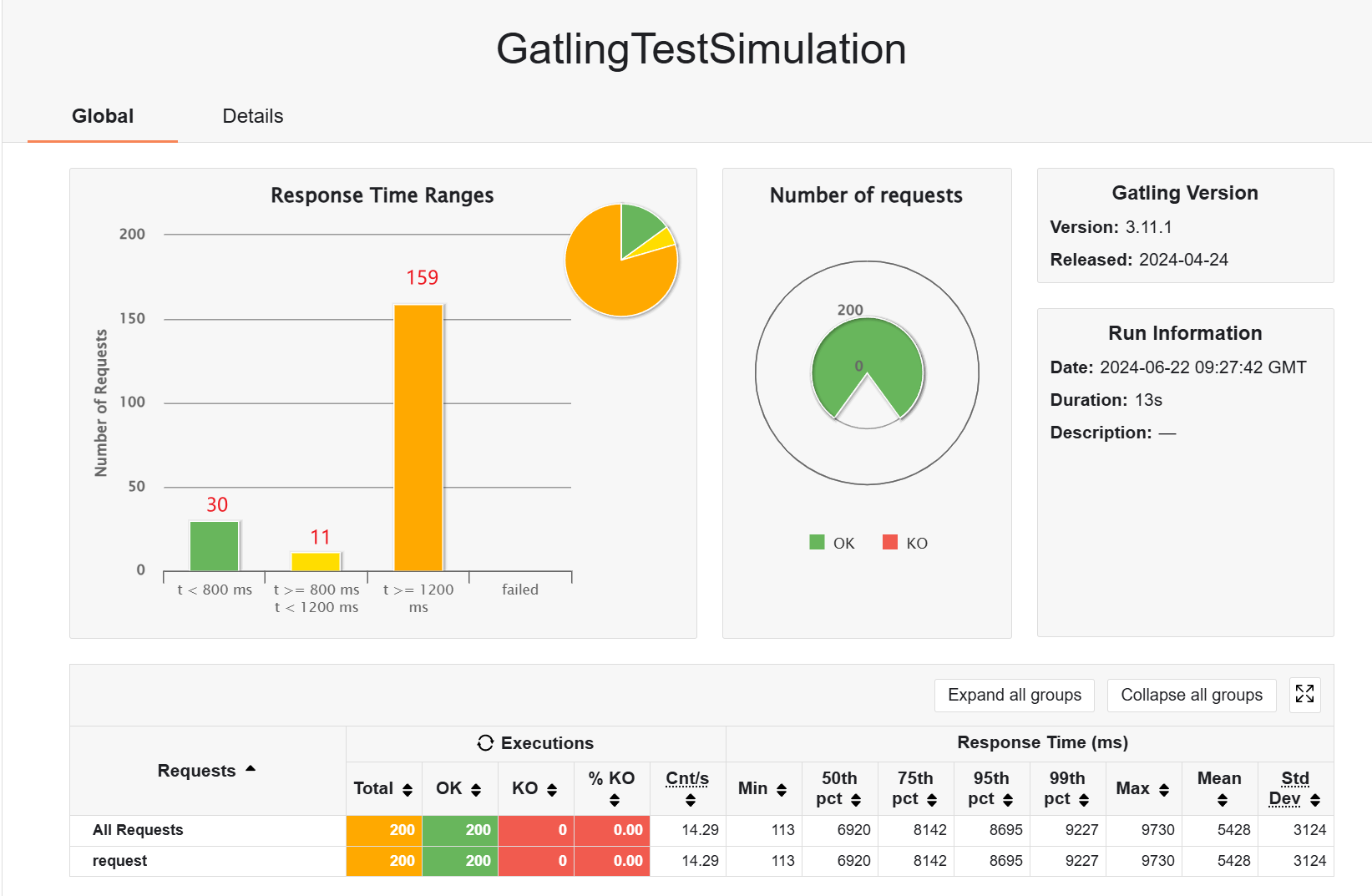
加缓存,并预热,OK,优势尽显
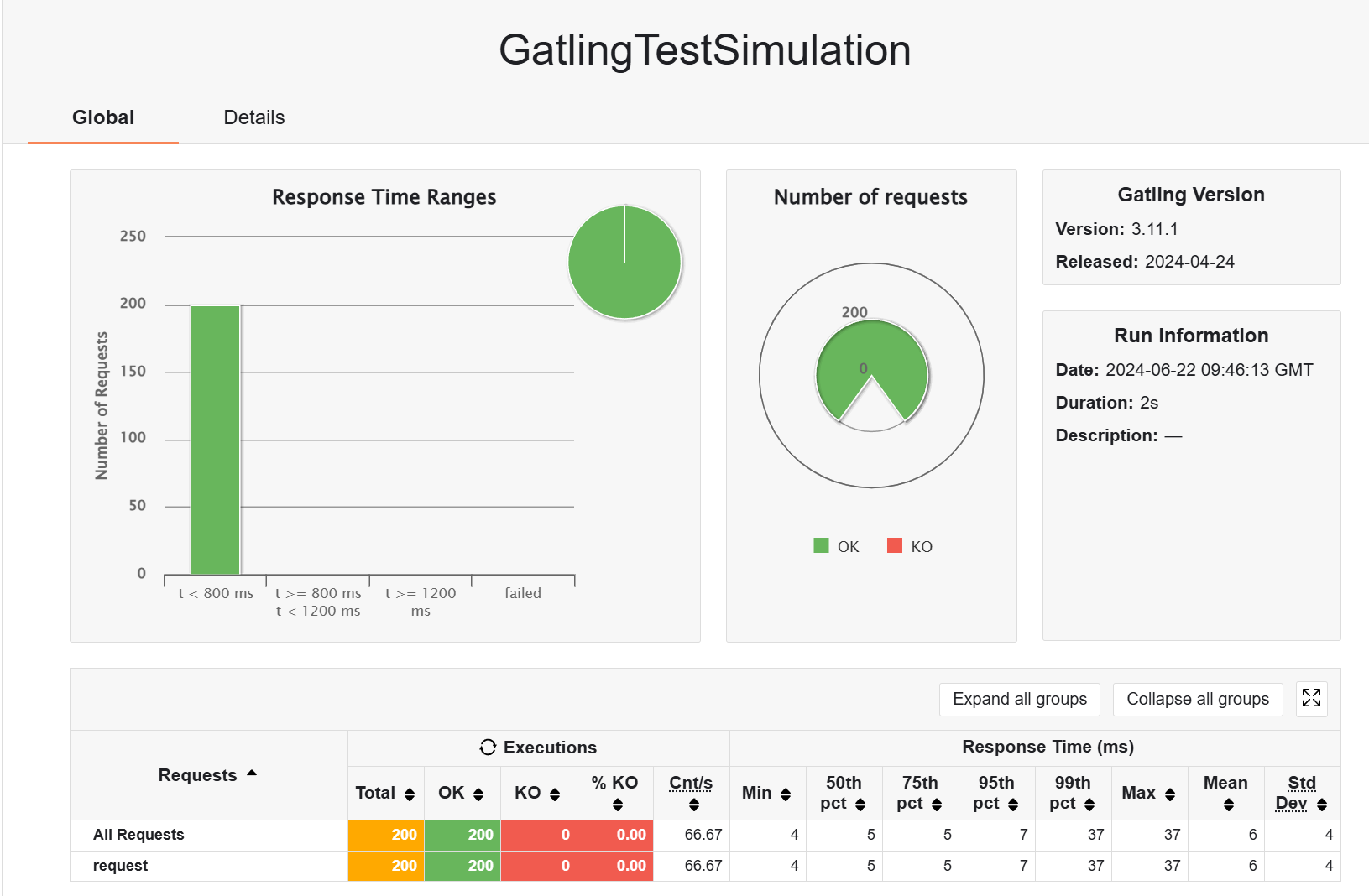
换回云服务器的 redis,结果依然符合预期,只是比本地的慢一点
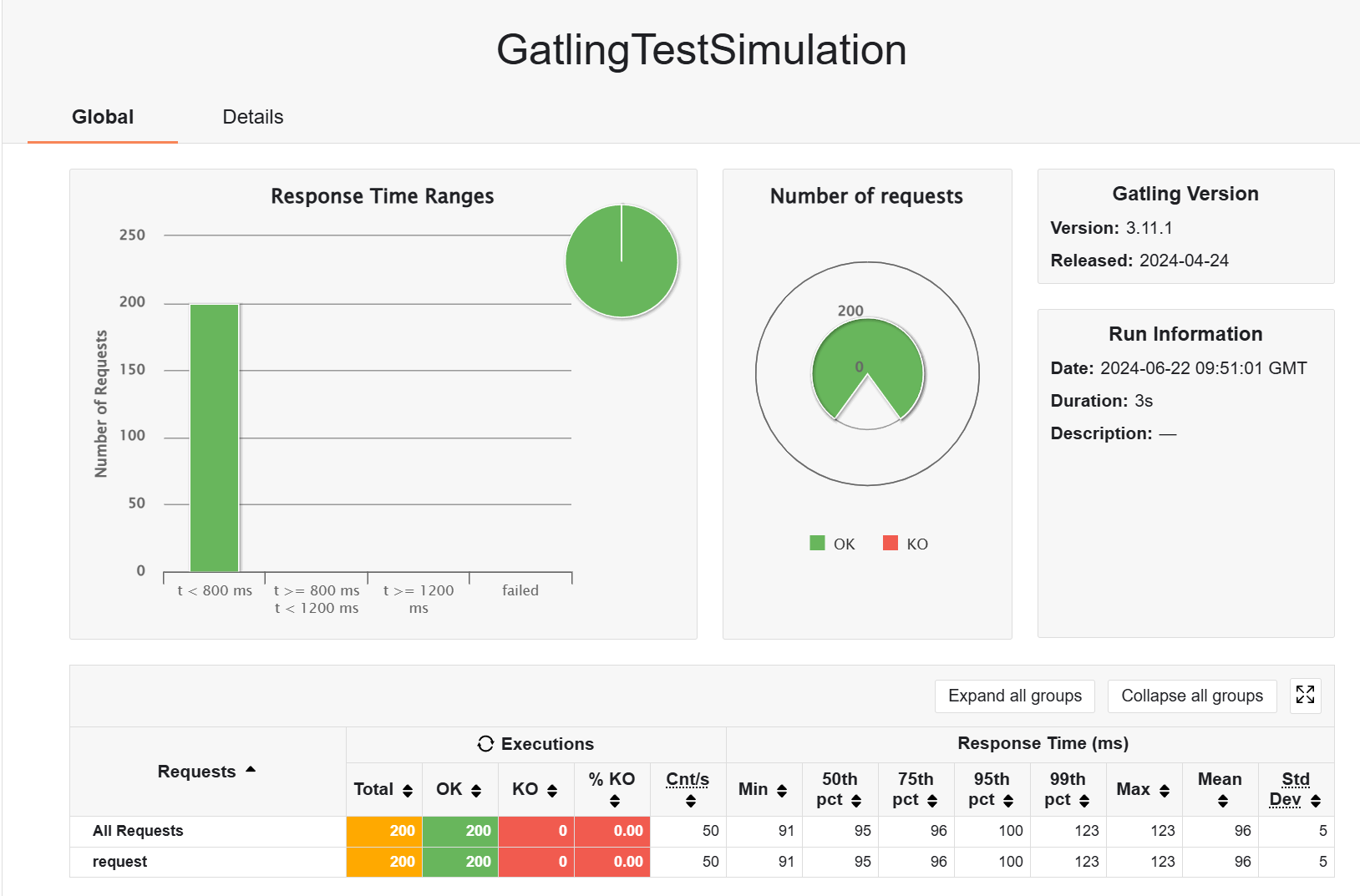
然后测试取一页商品的,先看看预热阶段的表现(查表 + 存到 redis)
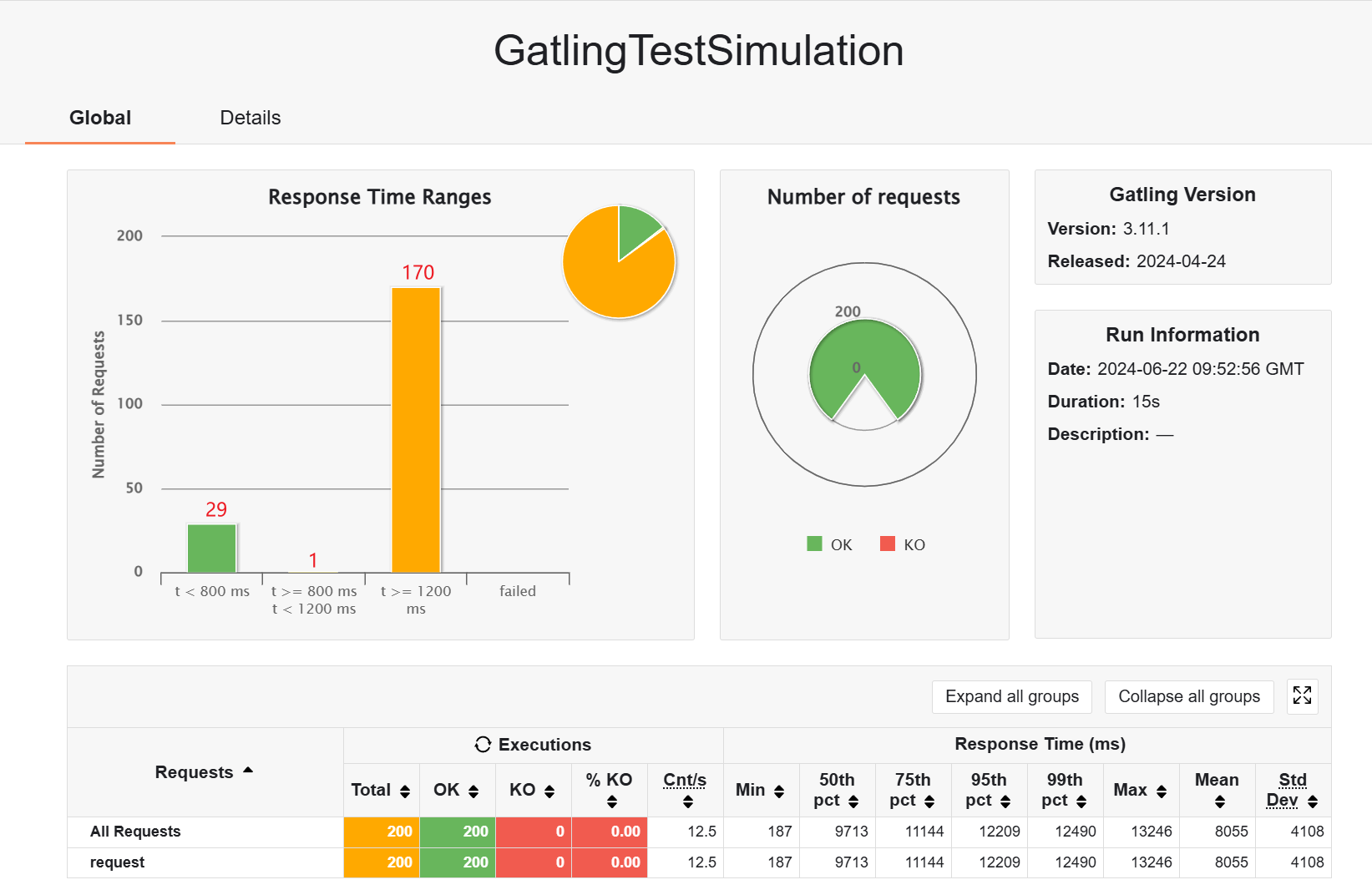
然后看缓存的作用,优势明显
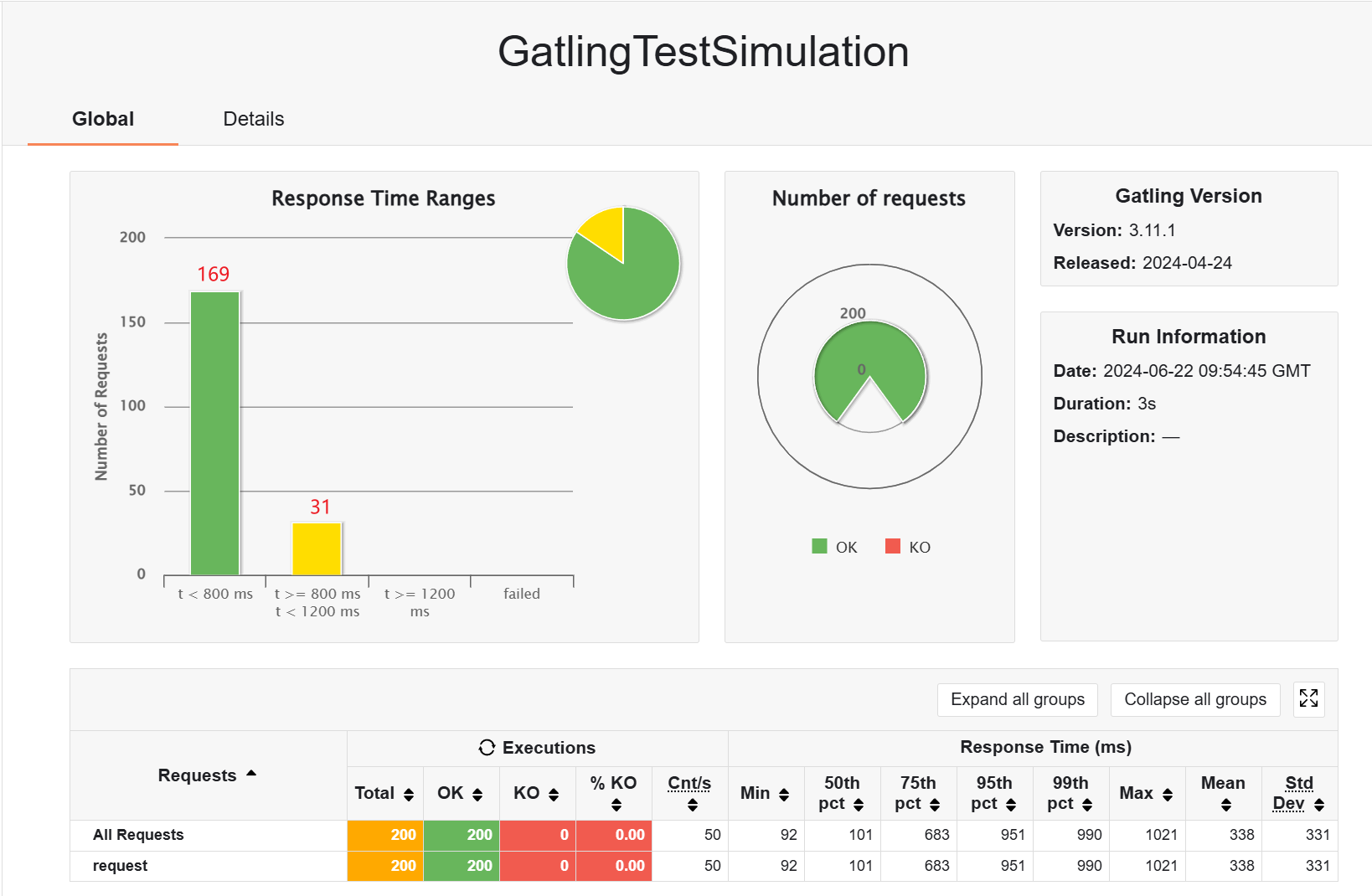
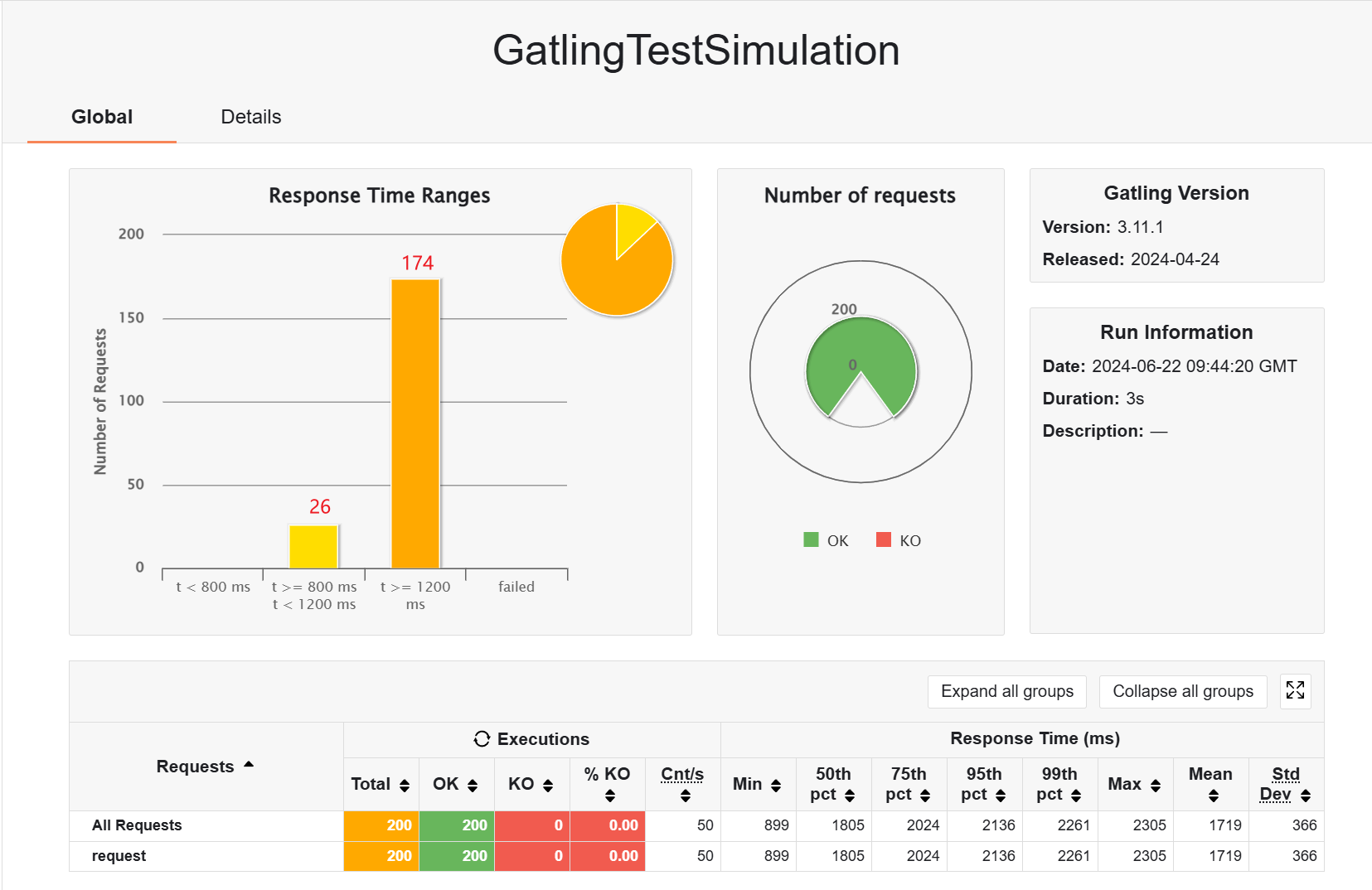
其实在响应式架构中,我比较关心瞬时并发用户的响应,接下来测试一下,不带缓存的情况下,250 个用户,有一些请求是失败的
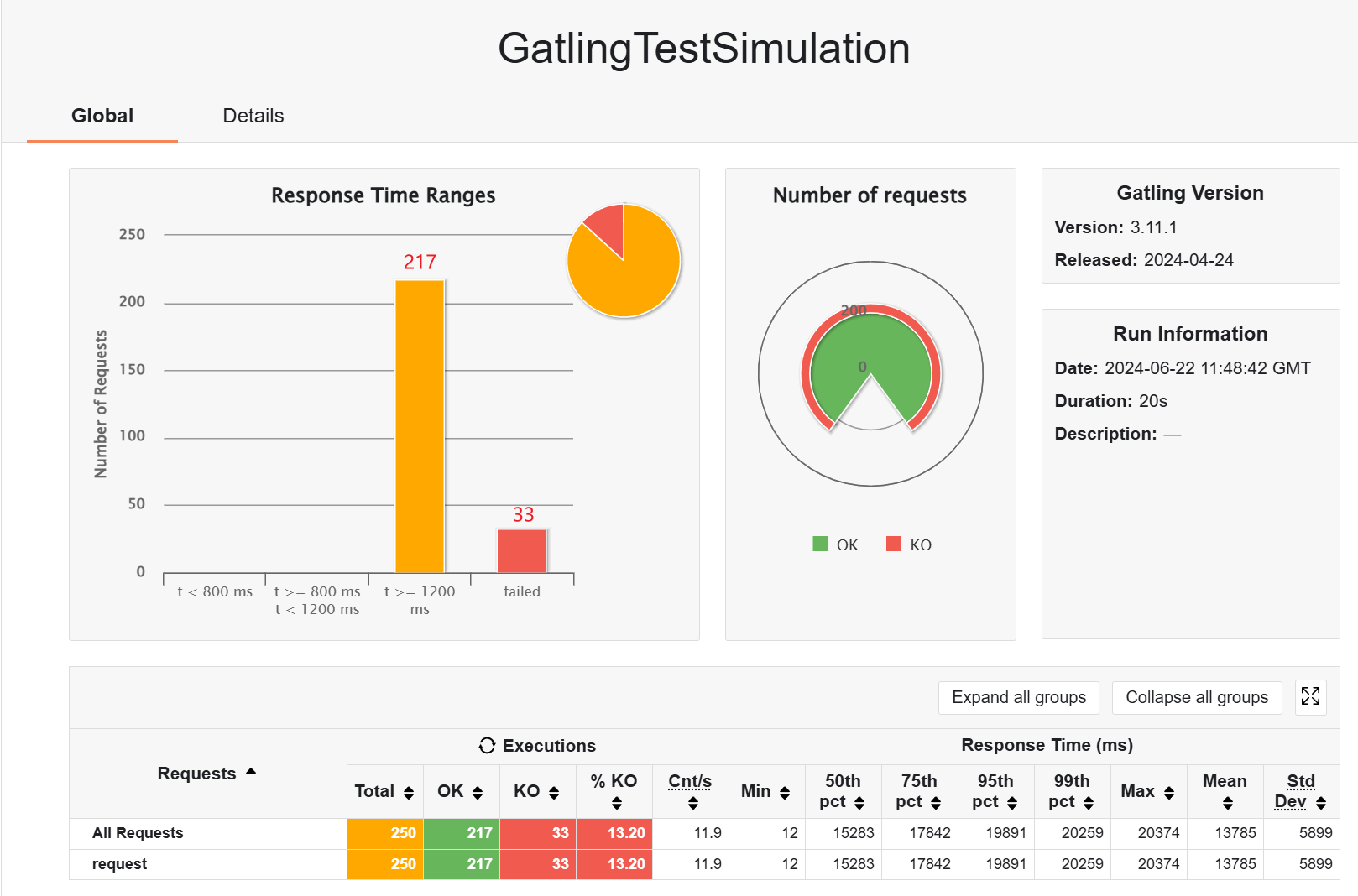
缓存之后,就不会失败了,有一些请求响应速度很快
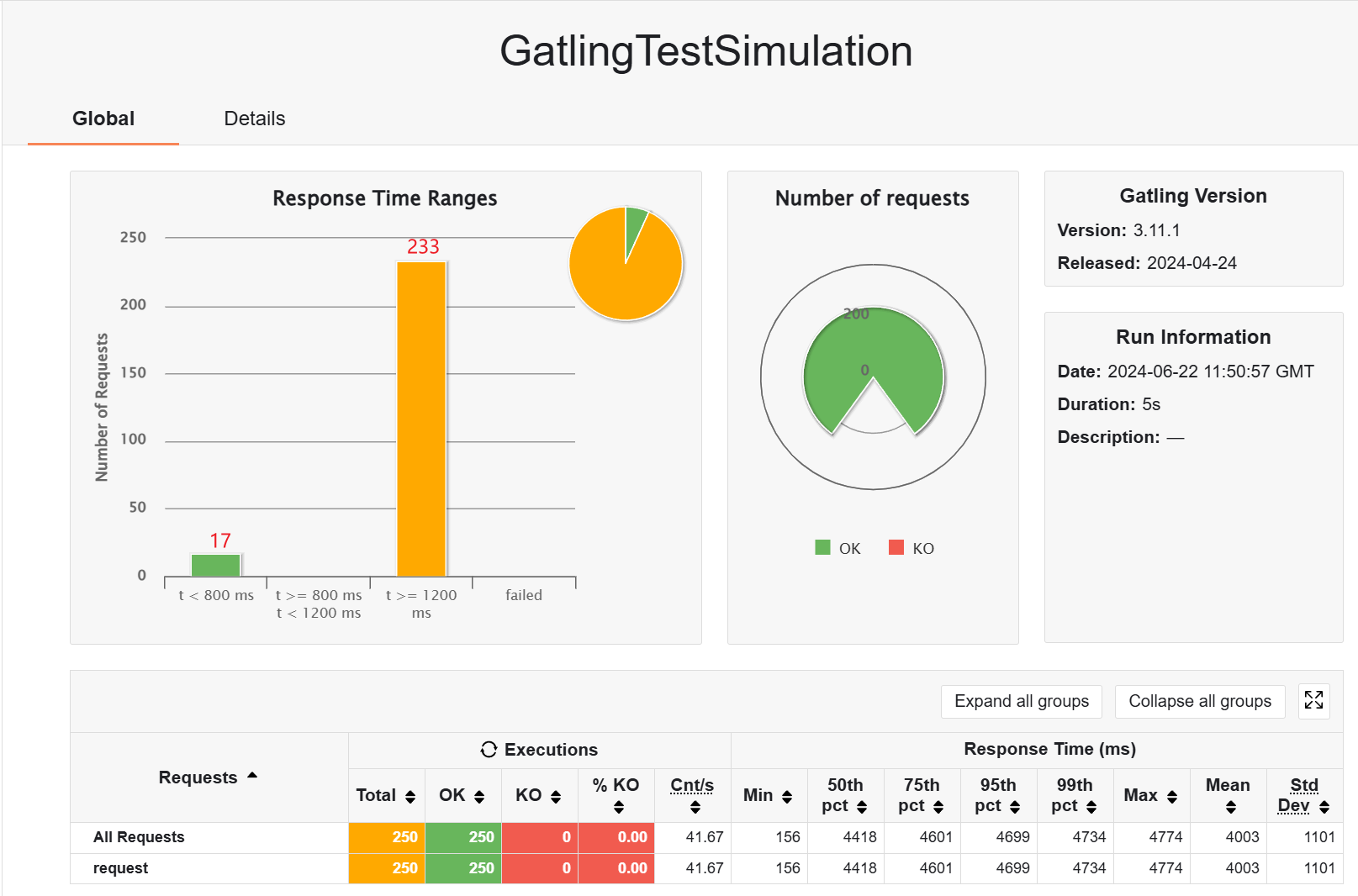
瞬时用户量为 200 时,不会发生 failed 的情况
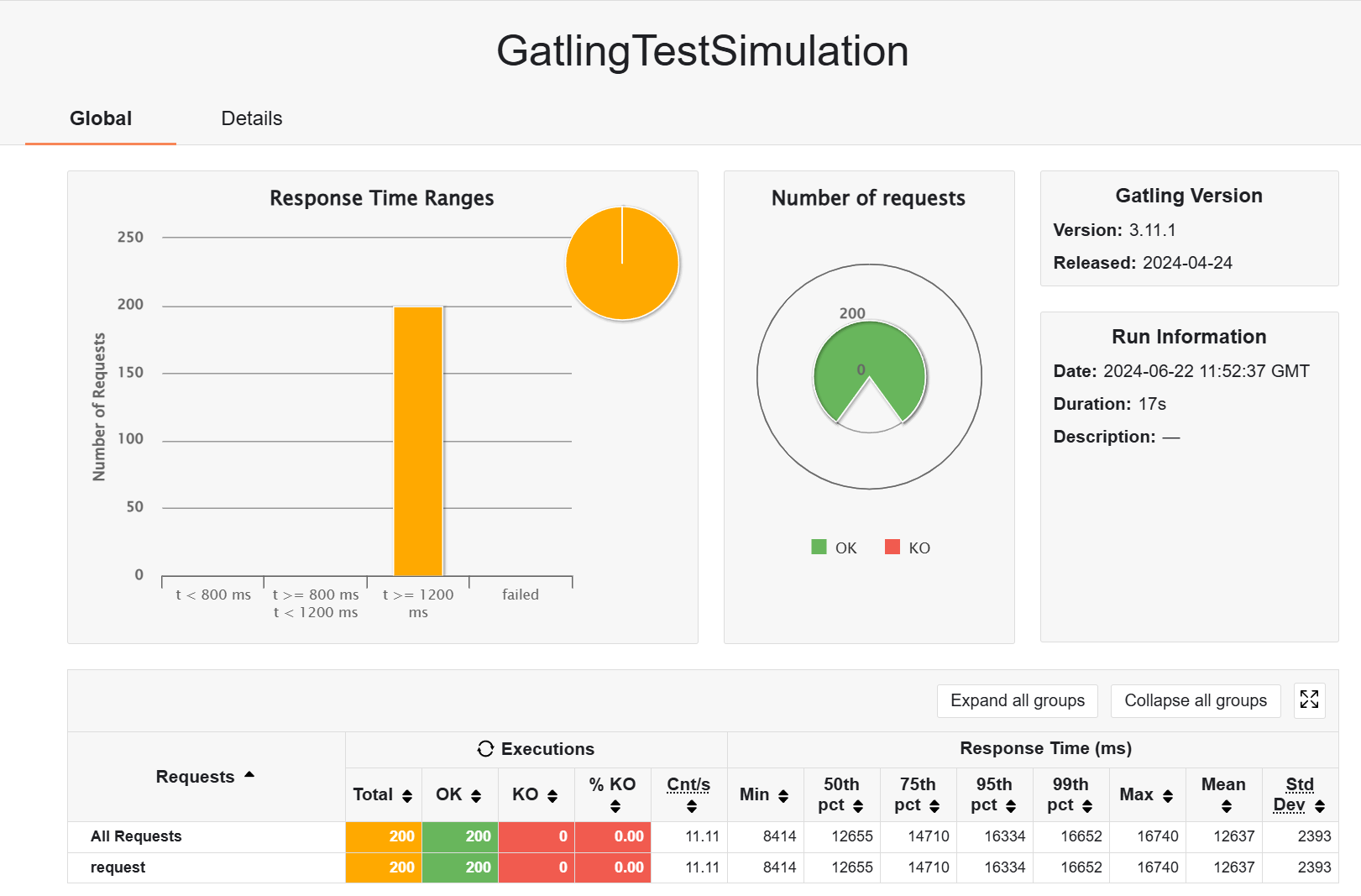
加了缓存之后,快是快了,但是没快多少
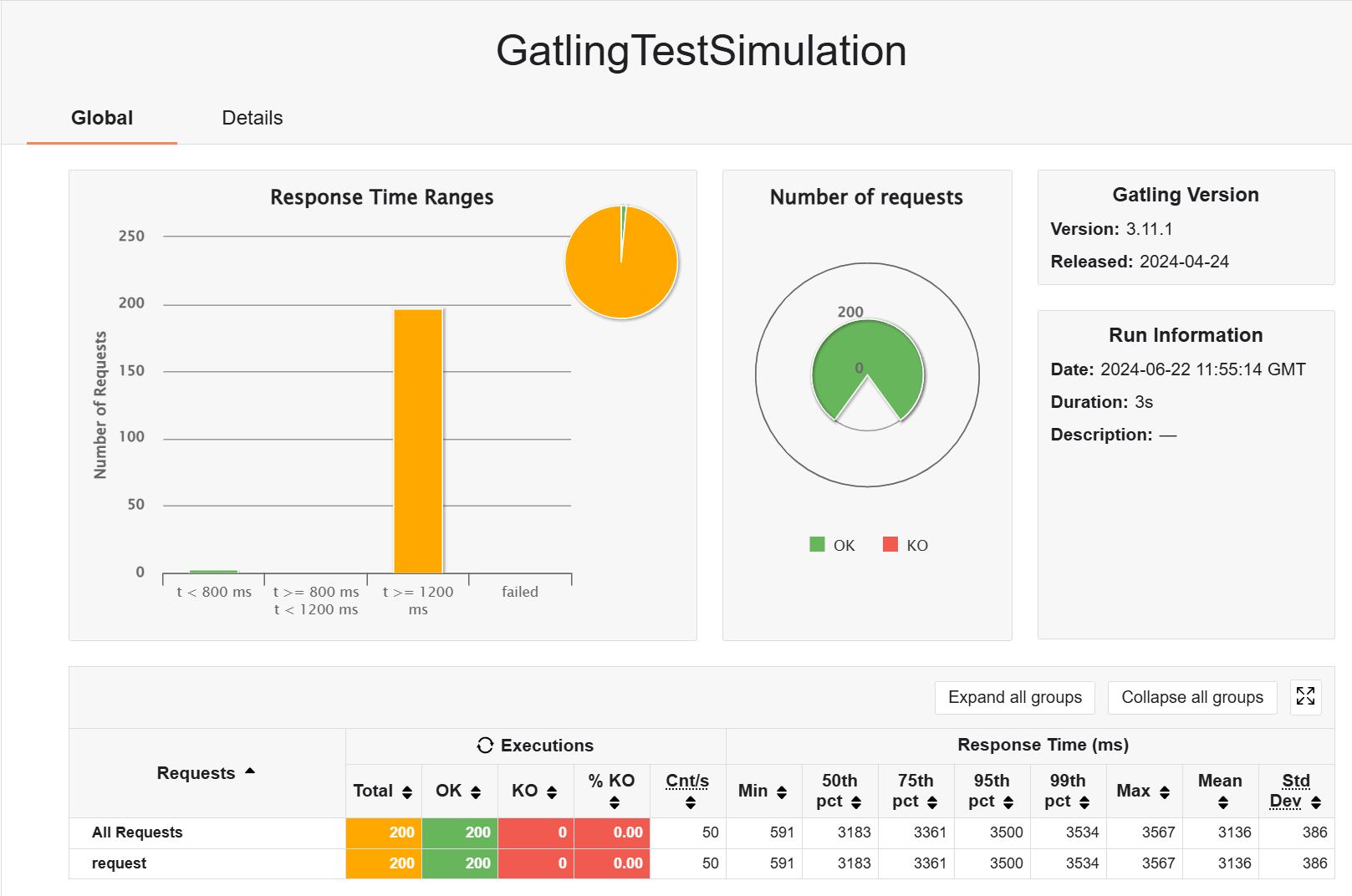
来对比一下,aw06 和 aw09 的架构,不加缓存,200 用户,3s
aw06:
- rampUsers
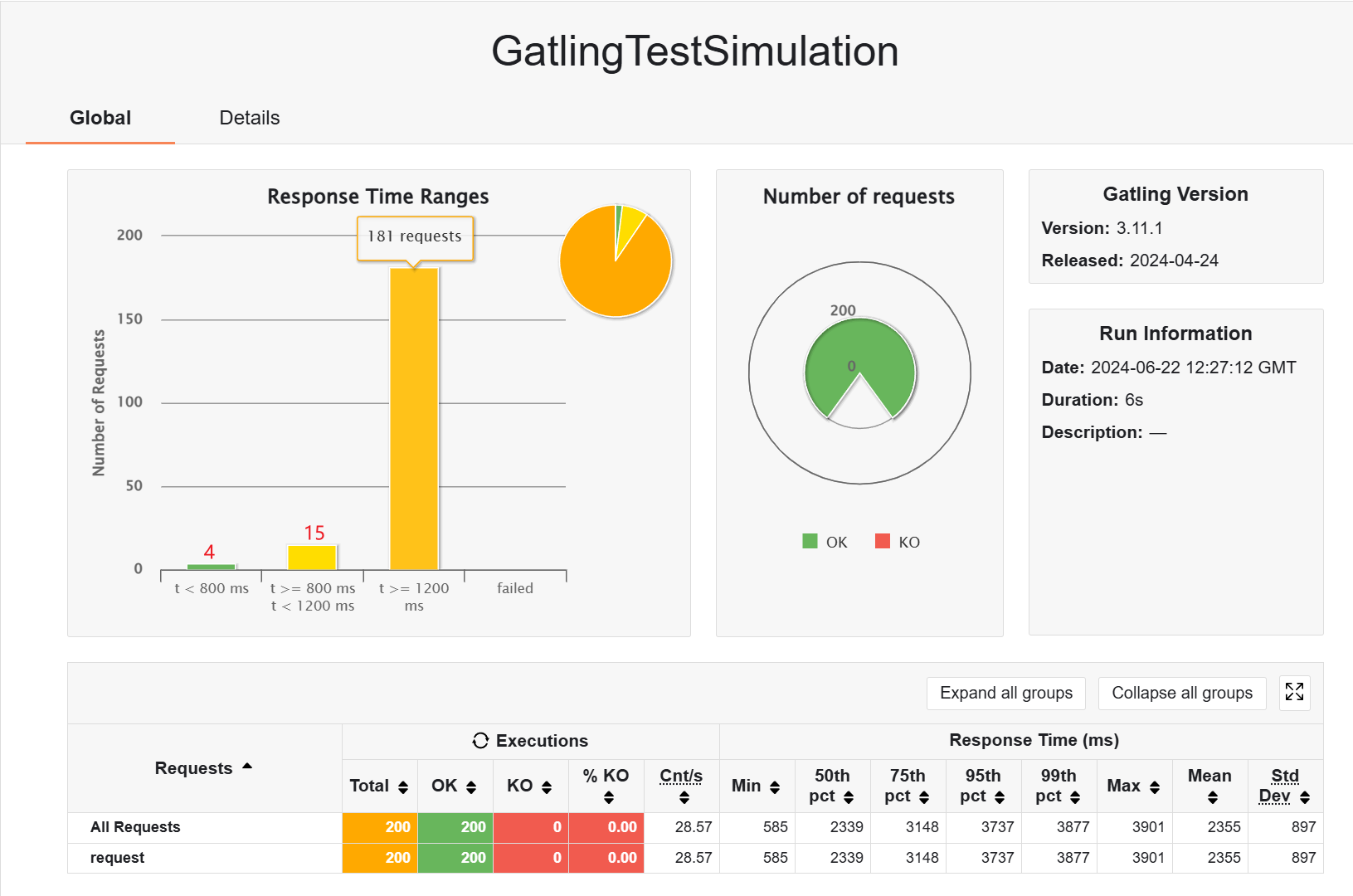
- atOnceUsers
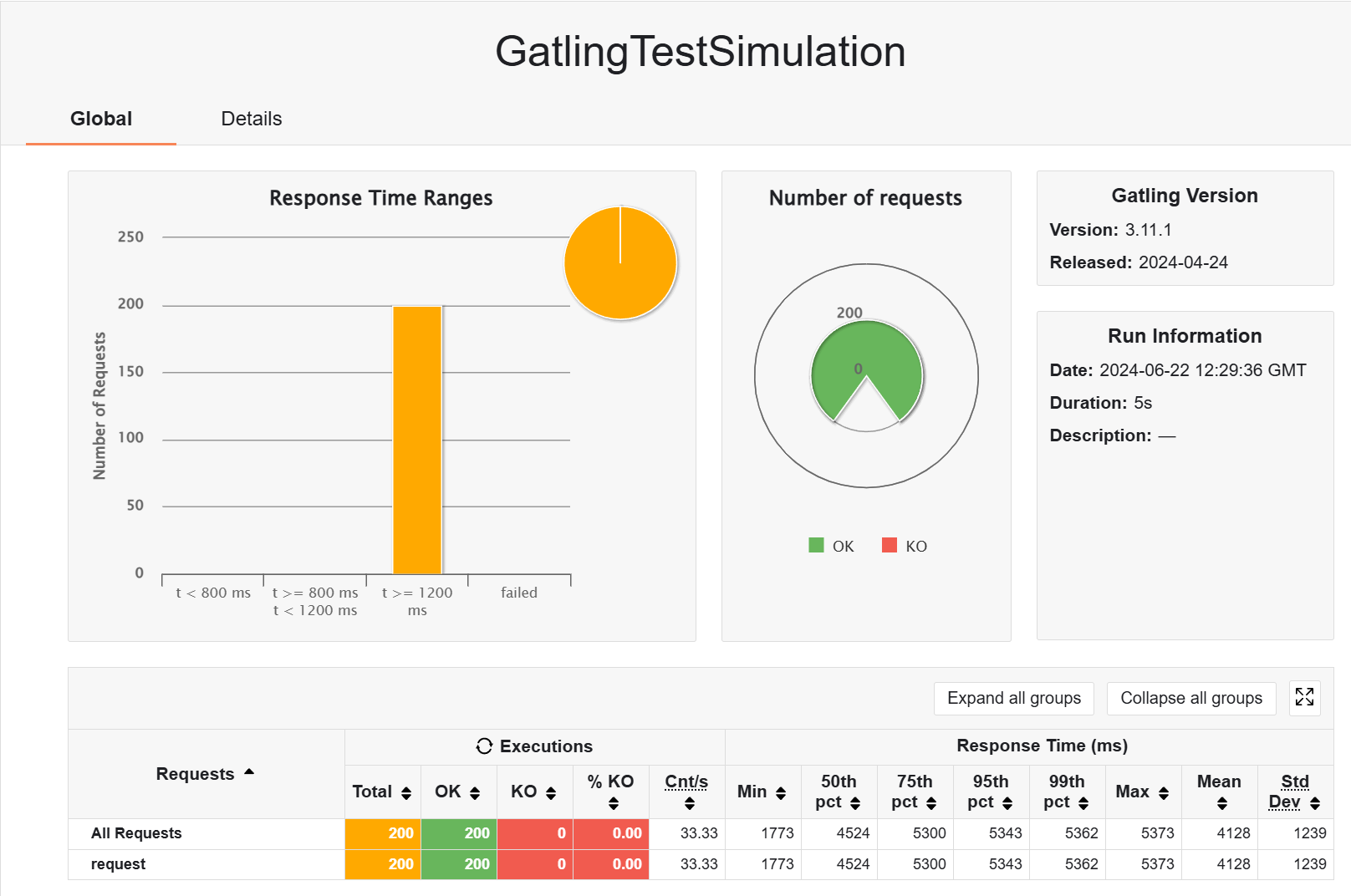
但是会出现报错
2024-06-22T20:29:41.780+08:00 ERROR 11284 --- [pos-product] [ol-2-thread-169] o.h.engine.jdbc.spi.SqlExceptionHelper : HikariPool-1 - Interrupted during connection acquisition
2024-06-22T20:29:41.780+08:00 ERROR 11284 --- [pos-product] [ol-2-thread-200] o.h.engine.jdbc.spi.SqlExceptionHelper : HikariPool-1 - Interrupted during connection acquisition
2024-06-22T20:29:41.780+08:00 WARN 11284 --- [pos-product] [ool-2-thread-77] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 0, SQLState: null
2024-06-22T20:29:41.780+08:00 WARN 11284 --- [pos-product] [ol-2-thread-183] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 0, SQLState: null看到的一个解释是(不保真):
目前只能大概推测,大量并发请求过来后,导致线程并发数量增加,但是因为 cpu 是一定的,会存在少数线程得不到响应。在超过一定时长后,被 HikariPool 组件认为是僵死线程,强制清理退出导致请求失败。
aw09:
- rampUsers
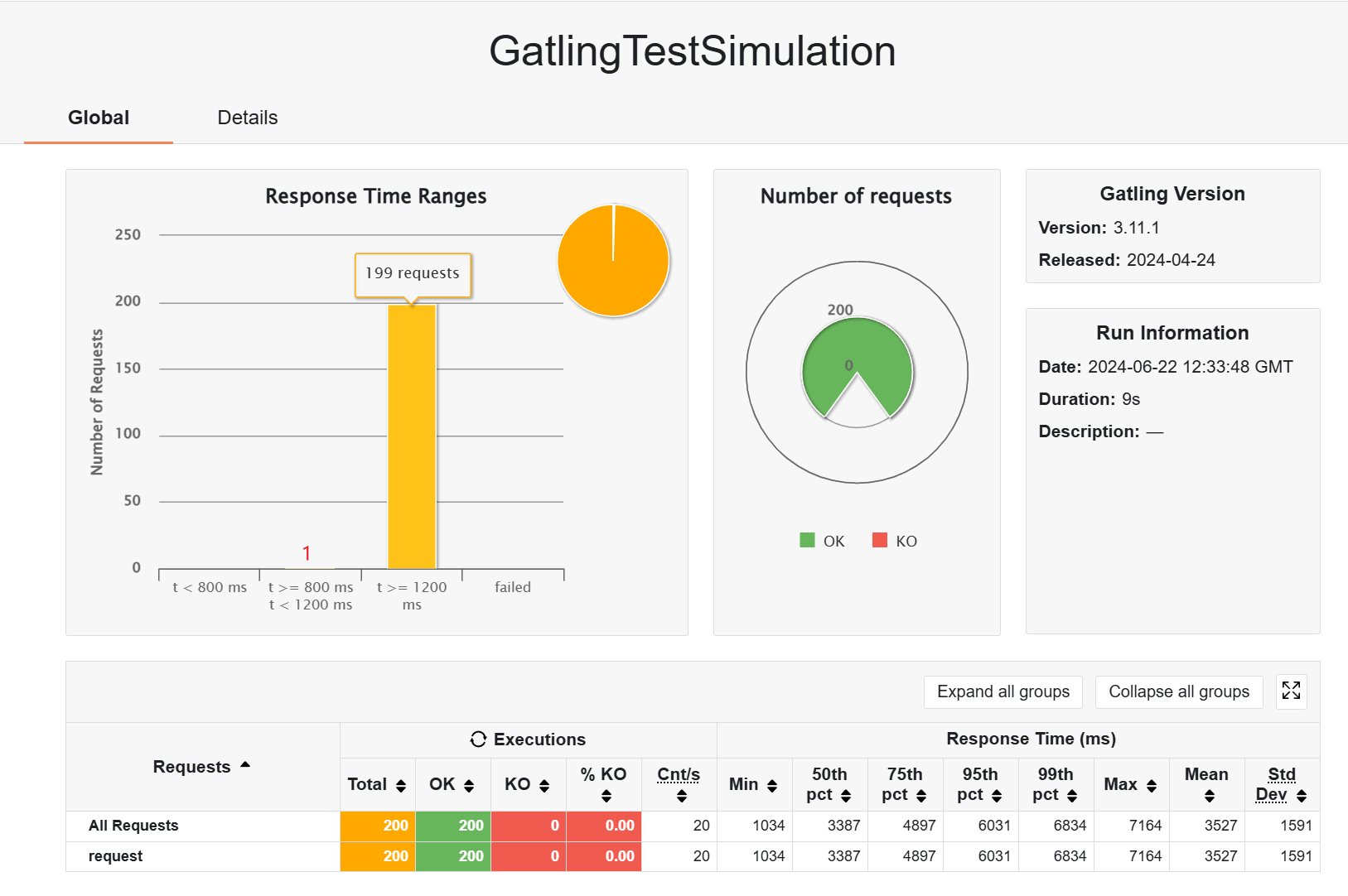
- atOnceUsers
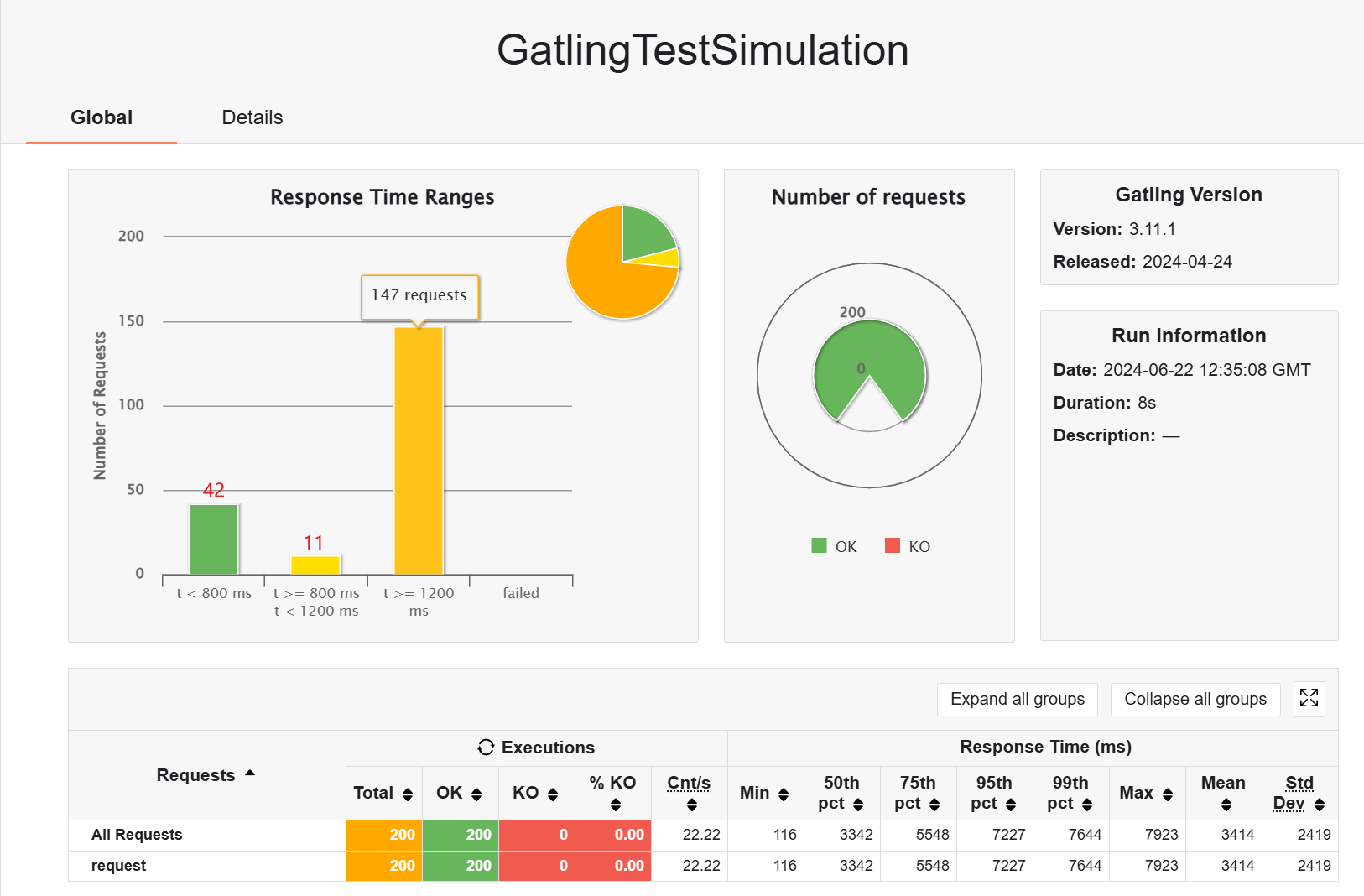
所以响应式体系的异步框架确实会在瞬时并发量大的情况下有更好的效果,如果是普通的话,和 mvc 架构的差不多